
ปัญญาประดิษฐ์และบิ๊กดาต้ามีศักยภาพในการค้นหาวิธีแก้ไขปัญหาระดับโลก ในขณะที่จัดลำดับความสำคัญของปัญหาในท้องถิ่นและเปลี่ยนแปลงโลกด้วยวิธีที่ลึกซึ้งมากมาย AI นำโซลูชันมาสู่ทุกคนและในทุกสถานที่ ตั้งแต่บ้านไปจนถึงที่ทำงาน เอไอคอมพิวเตอร์ด้วย เครื่องเรียนรู้ การฝึกอบรมสามารถจำลองพฤติกรรมที่ชาญฉลาดและการสนทนาในลักษณะอัตโนมัติและเป็นส่วนตัว
ถึงกระนั้น AI ประสบปัญหาการรวมเข้าด้วยกันและมักมีอคติ โชคดีที่มุ่งเน้นไปที่ จริยธรรมปัญญาประดิษฐ์ สามารถนำไปสู่ความเป็นไปได้ใหม่ ๆ ในแง่ของความหลากหลายและการรวมโดยการกำจัดอคติโดยไม่รู้ตัวผ่านข้อมูลการฝึกอบรมที่หลากหลาย
ความสำคัญของความหลากหลายในข้อมูลการฝึกอบรม AI
 ความหลากหลายและคุณภาพของข้อมูลการฝึกอบรมมีความเกี่ยวข้องกัน เนื่องจากข้อมูลหนึ่งส่งผลต่ออีกข้อมูลหนึ่งและส่งผลต่อผลลัพธ์ของโซลูชัน AI ความสำเร็จของโซลูชัน AI ขึ้นอยู่กับ ข้อมูลที่หลากหลาย มันถูกฝึกฝนมา ความหลากหลายของข้อมูลป้องกันไม่ให้ AI ใช้งานมากเกินไป หมายความว่าโมเดลจะดำเนินการหรือเรียนรู้จากข้อมูลที่ใช้ในการฝึกอบรมเท่านั้น ด้วยการโอเวอร์ฟิต แบบจำลอง AI ไม่สามารถให้ผลลัพธ์เมื่อทดสอบกับข้อมูลที่ไม่ได้ใช้ในการฝึกอบรม
ความหลากหลายและคุณภาพของข้อมูลการฝึกอบรมมีความเกี่ยวข้องกัน เนื่องจากข้อมูลหนึ่งส่งผลต่ออีกข้อมูลหนึ่งและส่งผลต่อผลลัพธ์ของโซลูชัน AI ความสำเร็จของโซลูชัน AI ขึ้นอยู่กับ ข้อมูลที่หลากหลาย มันถูกฝึกฝนมา ความหลากหลายของข้อมูลป้องกันไม่ให้ AI ใช้งานมากเกินไป หมายความว่าโมเดลจะดำเนินการหรือเรียนรู้จากข้อมูลที่ใช้ในการฝึกอบรมเท่านั้น ด้วยการโอเวอร์ฟิต แบบจำลอง AI ไม่สามารถให้ผลลัพธ์เมื่อทดสอบกับข้อมูลที่ไม่ได้ใช้ในการฝึกอบรม
สถานะปัจจุบันของการฝึกอบรม AI ข้อมูล
ความไม่เท่าเทียมกันหรือการขาดความหลากหลายในข้อมูลจะนำไปสู่โซลูชัน AI ที่ไม่ยุติธรรม ผิดจริยธรรม และไม่ครอบคลุม ซึ่งอาจทำให้การเลือกปฏิบัติรุนแรงขึ้น แต่ความหลากหลายในข้อมูลเกี่ยวข้องกับโซลูชัน AI อย่างไรและเพราะเหตุใด
การแสดงที่ไม่เท่ากันของทุกชนชั้นนำไปสู่การระบุใบหน้าที่ไม่ถูกต้อง กรณีสำคัญประการหนึ่งคือ Google Photos ซึ่งจำแนกคู่รักผิวดำว่าเป็น 'กอริลล่า' และ Meta แจ้งให้ผู้ใช้ดูวิดีโอของชายผิวดำว่าผู้ใช้ต้องการ 'ดูวิดีโอของไพรเมตต่อไปหรือไม่'
ตัวอย่างเช่น การจำแนกชนกลุ่มน้อยทางชาติพันธุ์หรือเชื้อชาติที่ไม่ถูกต้องหรือไม่เหมาะสม โดยเฉพาะอย่างยิ่งในแชทบอท อาจส่งผลให้เกิดอคติในระบบการฝึกอบรม AI ตามรายงานปี 2019 ระบบการเลือกปฏิบัติ – เพศ เชื้อชาติ อำนาจใน AIครู AI มากกว่า 80% เป็นผู้ชาย นักวิจัย AI ผู้หญิงบน FB มีเพียง 15% และ 10% บน Google
ผลกระทบของข้อมูลการฝึกอบรมที่หลากหลายต่อประสิทธิภาพของ AI
 การละกลุ่มและชุมชนเฉพาะออกจากการแสดงข้อมูลอาจนำไปสู่อัลกอริทึมที่เบ้
การละกลุ่มและชุมชนเฉพาะออกจากการแสดงข้อมูลอาจนำไปสู่อัลกอริทึมที่เบ้
อคติของข้อมูลมักถูกนำเข้าสู่ระบบข้อมูลโดยไม่ตั้งใจ – โดยการสุ่มตัวอย่างต่ำกว่าเชื้อชาติหรือบางกลุ่ม เมื่อระบบจดจำใบหน้าได้รับการฝึกอบรมบนใบหน้าที่หลากหลาย ระบบจะช่วยให้โมเดลระบุลักษณะเฉพาะ เช่น ตำแหน่งของอวัยวะบนใบหน้าและสีต่างๆ
ผลลัพธ์อีกประการหนึ่งของการมีความถี่ของฉลากที่ไม่สมดุลคือระบบอาจถือว่าส่วนน้อยเป็นความผิดปกติเมื่อได้รับแรงดันเพื่อสร้างเอาต์พุตภายในเวลาอันสั้น
บรรลุความหลากหลายในข้อมูลการฝึกอบรม AI
ในทางกลับกัน การสร้างชุดข้อมูลที่หลากหลายก็เป็นเรื่องที่ท้าทายเช่นกัน การขาดข้อมูลที่แท้จริงในบางชั้นเรียนอาจนำไปสู่การเป็นตัวแทน สามารถบรรเทาได้โดยทำให้ทีมนักพัฒนา AI มีความหลากหลายมากขึ้นในด้านทักษะ ชาติพันธุ์ เชื้อชาติ เพศ ระเบียบวินัย และอื่นๆ ยิ่งไปกว่านั้น วิธีที่เหมาะสมที่สุดในการจัดการกับปัญหาความหลากหลายของข้อมูลใน AI คือการเผชิญหน้ากับมันจากคำพูดแทนที่จะพยายามแก้ไขสิ่งที่ทำไปแล้ว – ผสมผสานความหลากหลายในขั้นตอนการรวบรวมข้อมูลและการดูแลจัดการ
โดยไม่คำนึงว่าจะโฆษณาเกี่ยวกับ AI อย่างไร มันยังคงขึ้นอยู่กับข้อมูลที่รวบรวม เลือก และฝึกฝนโดยมนุษย์ อคติที่มีมาแต่กำเนิดในมนุษย์จะสะท้อนให้เห็นในข้อมูลที่มนุษย์รวบรวมไว้ และความลำเอียงโดยไม่รู้ตัวนี้คืบคลานเข้าสู่โมเดล ML ด้วยเช่นกัน
ขั้นตอนในการรวบรวมและจัดการข้อมูลการฝึกอบรมที่หลากหลาย
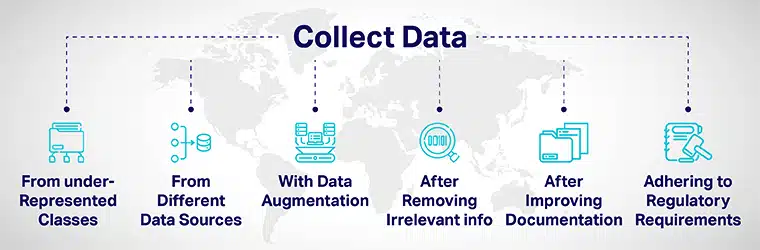
ความหลากหลายของข้อมูล สามารถทำได้โดย:
- เพิ่มข้อมูลให้มากขึ้นจากคลาสที่ไม่ได้เป็นตัวแทนและแสดงโมเดลของคุณต่อจุดข้อมูลต่างๆ
- โดยรวบรวมข้อมูลจากแหล่งข้อมูลต่างๆ
- โดยการเพิ่มข้อมูลหรือการดัดแปลงชุดข้อมูลเพื่อเพิ่ม/รวมจุดข้อมูลใหม่ที่แตกต่างจากจุดข้อมูลเดิมอย่างชัดเจน
- เมื่อจ้างผู้สมัครสำหรับกระบวนการพัฒนา AI ให้ลบข้อมูลที่ไม่เกี่ยวข้องกับงานทั้งหมดออกจากใบสมัคร
- การปรับปรุงความโปร่งใสและความรับผิดชอบโดยการปรับปรุงเอกสารของการพัฒนาและการประเมินแบบจำลอง
- แนะนำกฎระเบียบเพื่อสร้างความหลากหลายและ ความครอบคลุมใน AI ระบบตั้งแต่ระดับรากหญ้า รัฐบาลหลายประเทศได้พัฒนาแนวทางเพื่อให้แน่ใจว่ามีความหลากหลายและลดอคติของ AI ที่สามารถให้ผลลัพธ์ที่ไม่เป็นธรรม
[ ยังอ่าน: เรียนรู้เพิ่มเติมเกี่ยวกับกระบวนการรวบรวมข้อมูลการฝึกอบรม AI ]
สรุป
ปัจจุบัน มีบริษัทเทคโนโลยีขนาดใหญ่และศูนย์การเรียนรู้เพียงไม่กี่แห่งเท่านั้นที่มีส่วนร่วมในการพัฒนาโซลูชัน AI พื้นที่ชนชั้นสูงเหล่านี้เต็มไปด้วยการกีดกัน การเลือกปฏิบัติ และความลำเอียง อย่างไรก็ตาม สิ่งเหล่านี้คือช่องว่างที่ AI กำลังได้รับการพัฒนา และตรรกะที่อยู่เบื้องหลังระบบ AI ขั้นสูงเหล่านี้เต็มไปด้วยความลำเอียง การเลือกปฏิบัติ และการกีดกันที่เหมือนกันซึ่งเกิดจากกลุ่มคนที่อยู่ภายใต้ตัวแทน
ในขณะที่พูดถึงความหลากหลายและการไม่เลือกปฏิบัติ สิ่งสำคัญคือต้องตั้งคำถามถึงผู้คนที่ได้รับประโยชน์และเป็นอันตรายต่อผู้คน นอกจากนี้ เราควรพิจารณาว่าใครเป็นผู้เสียเปรียบ – โดยการบังคับความคิดของ 'คนปกติ' AI อาจทำให้ 'คนอื่น' ตกอยู่ในความเสี่ยง
การพูดถึงความหลากหลายในข้อมูล AI โดยไม่ยอมรับความสัมพันธ์เชิงอำนาจ ความเสมอภาค และความยุติธรรมจะไม่แสดงภาพรวม เพื่อให้เข้าใจขอบเขตของความหลากหลายในข้อมูลการฝึกอบรมของ AI อย่างถ่องแท้ และวิธีที่มนุษย์และ AI สามารถร่วมกันบรรเทาวิกฤตนี้ได้ ติดต่อวิศวกรที่ Shaip. เรามีวิศวกร AI หลากหลายที่สามารถให้ข้อมูลไดนามิกและหลากหลายสำหรับโซลูชัน AI ของคุณ


