
AI, Big Data และ Machine Learning ยังคงมีอิทธิพลต่อผู้กำหนดนโยบาย ธุรกิจ วิทยาศาสตร์ สื่อ และอุตสาหกรรมต่างๆ ทั่วโลก รายงานแนะนำว่าอัตราการยอมรับ AI ทั่วโลกอยู่ที่ 35% ใน 2022 – เพิ่มขึ้นมากถึง 4% จากปี 2021 มีรายงานว่าบริษัทอีก 42% กำลังสำรวจประโยชน์มากมายของ AI สำหรับธุรกิจของตน
ขับเคลื่อนความคิดริเริ่ม AI มากมายและ เครื่องเรียนรู้ โซลูชั่นคือข้อมูล AI จะทำได้ดีเท่ากับข้อมูลที่ป้อนให้กับอัลกอริทึมเท่านั้น ข้อมูลที่มีคุณภาพต่ำอาจส่งผลให้เกิดผลลัพธ์ที่มีคุณภาพต่ำและการคาดคะเนที่ไม่ถูกต้อง
แม้ว่าจะได้รับความสนใจอย่างมากเกี่ยวกับการพัฒนาโซลูชัน ML และ AI แต่การตระหนักรู้ถึงสิ่งที่มีคุณสมบัติเป็นชุดข้อมูลที่มีคุณภาพยังขาดหายไป ในบทความนี้ เราจะสำรวจไทม์ไลน์ของ ข้อมูลการฝึกอบรม AI ที่มีคุณภาพ และระบุอนาคตของ AI ผ่านความเข้าใจในการรวบรวมและฝึกอบรมข้อมูล
คำจำกัดความของข้อมูลการฝึกอบรม AI
เมื่อสร้างโซลูชัน ML ปริมาณและคุณภาพของชุดข้อมูลการฝึกอบรมมีความสำคัญ ระบบ ML ไม่เพียงต้องการข้อมูลการฝึกอบรมแบบไดนามิก ไม่เป็นกลาง และมีค่าในปริมาณมากเท่านั้น แต่ยังต้องการข้อมูลจำนวนมากอีกด้วย
แต่ข้อมูลการฝึกอบรม AI คืออะไร?
ข้อมูลการฝึกอบรม AI คือชุดของข้อมูลที่มีป้ายกำกับซึ่งใช้ในการฝึกอัลกอริทึม ML เพื่อให้คาดการณ์ได้อย่างแม่นยำ ระบบ ML พยายามจดจำและระบุรูปแบบ ทำความเข้าใจความสัมพันธ์ระหว่างพารามิเตอร์ ตัดสินใจที่จำเป็น และประเมินตามข้อมูลการฝึกอบรม
ยกตัวอย่างรถยนต์ไร้คนขับ เป็นต้น ชุดข้อมูลการฝึกอบรมสำหรับโมเดล ML ที่ขับเคลื่อนด้วยตนเองควรมีรูปภาพและวิดีโอที่มีป้ายกำกับของรถยนต์ คนเดินถนน ป้ายถนน และยานพาหนะอื่นๆ
กล่าวโดยย่อ เพื่อปรับปรุงคุณภาพของอัลกอริทึม ML คุณต้องใช้ข้อมูลการฝึกอบรมที่มีโครงสร้างดี มีคำอธิบายประกอบ และมีป้ายกำกับในปริมาณมาก
ความสำคัญของข้อมูลการฝึกอบรมที่มีคุณภาพและวิวัฒนาการ
ข้อมูลการฝึกอบรมคุณภาพสูงเป็นข้อมูลสำคัญในการพัฒนาแอป AI และ ML ข้อมูลถูกรวบรวมจากแหล่งต่าง ๆ และนำเสนอในรูปแบบที่ไม่เป็นระเบียบซึ่งไม่เหมาะสมสำหรับจุดประสงค์ของการเรียนรู้ด้วยเครื่อง ข้อมูลการฝึกอบรมที่มีคุณภาพ – มีป้ายกำกับ คำอธิบายประกอบ และแท็ก – อยู่ในรูปแบบที่เป็นระเบียบเสมอ – เหมาะอย่างยิ่งสำหรับการฝึกอบรม ML
ข้อมูลการฝึกอบรมที่มีคุณภาพช่วยให้ระบบ ML สามารถจดจำวัตถุและจำแนกวัตถุตามคุณลักษณะที่กำหนดไว้ล่วงหน้าได้ง่ายขึ้น ชุดข้อมูลอาจให้ผลลัพธ์ของแบบจำลองที่ไม่ดีหากการจำแนกประเภทไม่ถูกต้อง
วันแรก ๆ ของข้อมูลการฝึกอบรม AI
แม้ว่า AI จะครองโลกธุรกิจและการวิจัยในปัจจุบัน แต่ยุคแรก ๆ ก่อนที่ ML จะครอบงำ ปัญญาประดิษฐ์ ค่อนข้างแตกต่างกัน
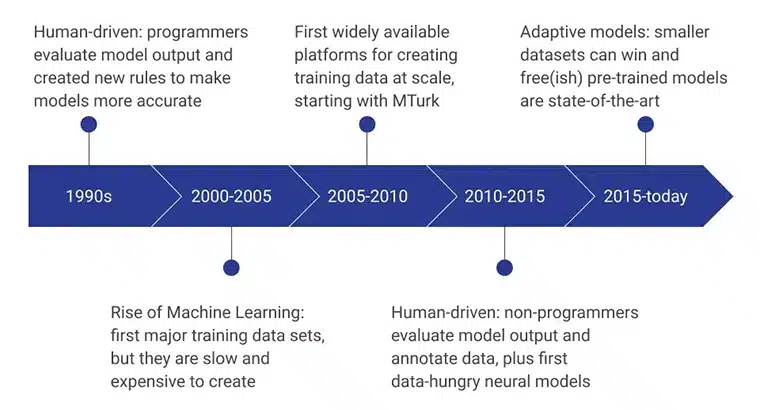
ขั้นตอนเริ่มต้นของข้อมูลการฝึกอบรม AI นั้นขับเคลื่อนโดยโปรแกรมเมอร์ของมนุษย์ที่ประเมินผลลัพธ์ของโมเดลโดยกำหนดกฎใหม่อย่างต่อเนื่องที่ทำให้โมเดลมีประสิทธิภาพมากขึ้น ในช่วงปี 2000 – 2005 ชุดข้อมูลหลักชุดแรกถูกสร้างขึ้น และเป็นกระบวนการที่ช้ามาก ต้องอาศัยทรัพยากร และมีราคาแพง ซึ่งนำไปสู่ชุดข้อมูลการฝึกอบรมที่ได้รับการพัฒนาตามขนาด และ MTurk ของ Amazon มีบทบาทสำคัญในการเปลี่ยนการรับรู้ของผู้คนต่อการรวบรวมข้อมูล ในขณะเดียวกัน การติดฉลากและคำอธิบายประกอบโดยมนุษย์ก็หายไปเช่นกัน
ในอีกไม่กี่ปีข้างหน้ามุ่งเน้นไปที่การสร้างและประเมินโมเดลข้อมูลที่ไม่ใช่โปรแกรมเมอร์ ปัจจุบัน มุ่งเน้นที่รูปแบบการฝึกอบรมล่วงหน้าที่พัฒนาขึ้นโดยใช้วิธีการรวบรวมข้อมูลการฝึกอบรมขั้นสูง
ปริมาณมากกว่าคุณภาพ
เมื่อประเมินความสมบูรณ์ของชุดข้อมูลการฝึกอบรม AI ในอดีต นักวิทยาศาสตร์ข้อมูลมุ่งเน้นที่ ปริมาณข้อมูลการฝึกอบรม AI คุณภาพเกินราคา
ตัวอย่างเช่น มีความเข้าใจผิดกันทั่วไปว่าฐานข้อมูลขนาดใหญ่ให้ผลลัพธ์ที่แม่นยำ เชื่อว่าปริมาณข้อมูลที่แท้จริงเป็นตัวบ่งชี้ที่ดีของมูลค่าของข้อมูล ปริมาณเป็นเพียงหนึ่งในปัจจัยหลักที่กำหนดมูลค่าของชุดข้อมูล - บทบาทของคุณภาพของข้อมูลได้รับการยอมรับ
ความตระหนักว่า คุณภาพของข้อมูล ขึ้นอยู่กับความสมบูรณ์ของข้อมูล ความน่าเชื่อถือ ความถูกต้อง ความพร้อมใช้ และความตรงต่อเวลาที่เพิ่มขึ้น สิ่งสำคัญที่สุดคือ ความเหมาะสมของข้อมูลสำหรับโครงการจะเป็นตัวกำหนดคุณภาพของข้อมูลที่รวบรวม
ข้อ จำกัด ของระบบ AI ในยุคแรก ๆ เนื่องจากข้อมูลการฝึกอบรมที่ไม่ดี
ข้อมูลการฝึกอบรมที่ไม่ดี ประกอบกับการขาดระบบคอมพิวเตอร์ขั้นสูง เป็นสาเหตุหนึ่งที่ทำให้สัญญาของระบบ AI ในยุคแรกๆ ไม่บรรลุผล
เนื่องจากขาดข้อมูลการฝึกอบรมที่มีคุณภาพ โซลูชัน ML จึงไม่สามารถระบุรูปแบบภาพที่ขัดขวางการพัฒนาการวิจัยทางประสาทได้อย่างแม่นยำ แม้ว่านักวิจัยหลายคนระบุคำมั่นสัญญาของการรู้จำภาษาพูด แต่การวิจัยและพัฒนาเครื่องมือรู้จำเสียงไม่สามารถบรรลุผลได้เนื่องจากขาดชุดข้อมูลเสียงพูด อุปสรรคสำคัญอีกประการหนึ่งในการพัฒนาเครื่องมือ AI ระดับไฮเอนด์คือการที่คอมพิวเตอร์ขาดความสามารถในการคำนวณและการจัดเก็บ
การเปลี่ยนแปลงไปสู่ข้อมูลการฝึกอบรมที่มีคุณภาพ
มีการเปลี่ยนแปลงอย่างเห็นได้ชัดในความตระหนักว่าคุณภาพของชุดข้อมูลมีความสำคัญ เพื่อให้ระบบ ML สามารถเลียนแบบสติปัญญาของมนุษย์และความสามารถในการตัดสินใจได้อย่างแม่นยำ ระบบจะต้องเติบโตด้วยข้อมูลการฝึกอบรมที่มีปริมาณมากและมีคุณภาพสูง
คิดว่าข้อมูล ML ของคุณเป็นแบบสำรวจ ยิ่งข้อมูลมากเท่าไร ตัวอย่างข้อมูล ขนาดการคาดการณ์ที่ดีขึ้น หากข้อมูลตัวอย่างไม่มีตัวแปรทั้งหมด อาจไม่รู้จักรูปแบบหรือให้ข้อสรุปที่ไม่ถูกต้อง
ความก้าวหน้าในเทคโนโลยี AI และความต้องการข้อมูลการฝึกอบรมที่ดีขึ้น
 ความก้าวหน้าในเทคโนโลยี AI กำลังเพิ่มความต้องการข้อมูลการฝึกอบรมที่มีคุณภาพ
ความก้าวหน้าในเทคโนโลยี AI กำลังเพิ่มความต้องการข้อมูลการฝึกอบรมที่มีคุณภาพความเข้าใจที่ว่าข้อมูลการฝึกอบรมที่ดีขึ้นจะเพิ่มโอกาสของโมเดล ML ที่เชื่อถือได้ ก่อให้เกิดวิธีการรวบรวมข้อมูล คำอธิบายประกอบ และการติดฉลากที่ดีขึ้น คุณภาพและความเกี่ยวข้องของข้อมูลส่งผลโดยตรงต่อคุณภาพของแบบจำลอง AI
 ความก้าวหน้าในเทคโนโลยี AI กำลังเพิ่มความต้องการข้อมูลการฝึกอบรมที่มีคุณภาพ
ความก้าวหน้าในเทคโนโลยี AI กำลังเพิ่มความต้องการข้อมูลการฝึกอบรมที่มีคุณภาพเพิ่มการมุ่งเน้นที่คุณภาพและความถูกต้องของข้อมูล
เพื่อให้โมเดล ML เริ่มให้ผลลัพธ์ที่ถูกต้อง ระบบจะป้อนชุดข้อมูลที่มีคุณภาพซึ่งผ่านขั้นตอนการปรับแต่งข้อมูลซ้ำๆ
ตัวอย่างเช่น มนุษย์อาจรู้จักสุนัขสายพันธุ์ใดสายพันธุ์หนึ่งได้ภายในเวลาไม่กี่วันหลังจากได้รับการแนะนำให้รู้จักกับสายพันธุ์นี้ ผ่านรูปภาพ วิดีโอ หรือสัมผัสด้วยตนเอง มนุษย์ใช้ประสบการณ์และข้อมูลที่เกี่ยวข้องเพื่อจดจำและดึงความรู้นี้มาใช้เมื่อจำเป็น ถึงกระนั้นก็ใช้งานไม่ได้ง่ายนักสำหรับเครื่องจักร เครื่องจะต้องได้รับการป้อนด้วยภาพที่มีคำอธิบายประกอบและติดป้ายอย่างชัดเจน – หลายร้อยหรือหลายพัน – ของสายพันธุ์นั้นๆ และสายพันธุ์อื่นๆ เพื่อให้เชื่อมต่อได้
แบบจำลอง AI คาดการณ์ผลลัพธ์โดยเชื่อมโยงข้อมูลที่ฝึกอบรมกับข้อมูลที่นำเสนอใน โลกแห่งความจริง. อัลกอริทึมจะไม่มีประโยชน์หากข้อมูลการฝึกอบรมไม่มีข้อมูลที่เกี่ยวข้อง
ความสำคัญของข้อมูลการฝึกอบรมที่หลากหลายและเป็นตัวแทน
ความหลากหลายของข้อมูลที่เพิ่มขึ้นยังเพิ่มความสามารถ ลดอคติ และเพิ่มการเป็นตัวแทนที่เท่าเทียมกันของทุกสถานการณ์ หากโมเดล AI ได้รับการฝึกโดยใช้ชุดข้อมูลที่เป็นเนื้อเดียวกัน คุณจะมั่นใจได้ว่าแอปพลิเคชันใหม่จะทำงานเพื่อวัตถุประสงค์เฉพาะและให้บริการกับประชากรที่เฉพาะเจาะจงเท่านั้นชุดข้อมูลอาจมีอคติต่อประชากร เชื้อชาติ เพศ ตัวเลือก และความคิดเห็นทางปัญญา ซึ่งอาจนำไปสู่แบบจำลองที่ไม่ถูกต้อง
สิ่งสำคัญคือต้องแน่ใจว่าโฟลว์ของกระบวนการเก็บรวบรวมข้อมูลทั้งหมด รวมถึงการเลือกกลุ่มหัวข้อ การดูแลจัดการ คำอธิบายประกอบ และการติดฉลาก มีความหลากหลายเพียงพอ สมดุล และเป็นตัวแทนของประชากร
 ความหลากหลายของข้อมูลที่เพิ่มขึ้นยังเพิ่มความสามารถ ลดอคติ และเพิ่มการเป็นตัวแทนที่เท่าเทียมกันของทุกสถานการณ์ หากโมเดล AI ได้รับการฝึกโดยใช้ชุดข้อมูลที่เป็นเนื้อเดียวกัน คุณจะมั่นใจได้ว่าแอปพลิเคชันใหม่จะทำงานเพื่อวัตถุประสงค์เฉพาะและให้บริการกับประชากรที่เฉพาะเจาะจงเท่านั้น
ความหลากหลายของข้อมูลที่เพิ่มขึ้นยังเพิ่มความสามารถ ลดอคติ และเพิ่มการเป็นตัวแทนที่เท่าเทียมกันของทุกสถานการณ์ หากโมเดล AI ได้รับการฝึกโดยใช้ชุดข้อมูลที่เป็นเนื้อเดียวกัน คุณจะมั่นใจได้ว่าแอปพลิเคชันใหม่จะทำงานเพื่อวัตถุประสงค์เฉพาะและให้บริการกับประชากรที่เฉพาะเจาะจงเท่านั้นอนาคตของข้อมูลการฝึกอบรม AI
ความสำเร็จในอนาคตของโมเดล AI ขึ้นอยู่กับคุณภาพและปริมาณของข้อมูลการฝึกที่ใช้ในการฝึกอัลกอริทึม ML สิ่งสำคัญคือต้องตระหนักว่าความสัมพันธ์ระหว่างคุณภาพข้อมูลและปริมาณนี้เป็นงานเฉพาะและไม่มีคำตอบที่แน่นอน
ในท้ายที่สุด ความเพียงพอของชุดข้อมูลการฝึกอบรมนั้นถูกกำหนดโดยความสามารถในการทำงานได้ดีอย่างน่าเชื่อถือตามวัตถุประสงค์ที่สร้างขึ้น
ความก้าวหน้าในการเก็บรวบรวมข้อมูลและเทคนิคการทำหมายเหตุประกอบ
เนื่องจาก ML มีความละเอียดอ่อนต่อข้อมูลที่ป้อน จึงจำเป็นอย่างยิ่งที่จะต้องปรับปรุงนโยบายการรวบรวมข้อมูลและการเพิ่มความคิดเห็น ข้อผิดพลาดในการรวบรวมข้อมูล การจัดการ การสื่อให้เข้าใจผิด การวัดที่ไม่สมบูรณ์ เนื้อหาที่ไม่ถูกต้อง การทำซ้ำข้อมูล และการวัดที่ผิดพลาดมีส่วนทำให้คุณภาพของข้อมูลไม่เพียงพอ
การรวบรวมข้อมูลอัตโนมัติผ่านการขุดข้อมูล การขูดเว็บ และการดึงข้อมูลกำลังปูทางไปสู่การสร้างข้อมูลที่รวดเร็วขึ้น นอกจากนี้ ชุดข้อมูลที่บรรจุไว้ล่วงหน้ายังทำหน้าที่เป็นเทคนิคการรวบรวมข้อมูลอย่างรวดเร็ว
คราวด์ซอร์สซิ่งเป็นวิธีการรวบรวมข้อมูลที่แหวกแนวอีกวิธีหนึ่ง แม้ว่าจะไม่สามารถรับรองความถูกต้องของข้อมูลได้ แต่ก็เป็นเครื่องมือที่ยอดเยี่ยมสำหรับการรวบรวมภาพลักษณ์สาธารณะ ในที่สุดก็เชี่ยวชาญ การเก็บรวบรวมข้อมูล ผู้เชี่ยวชาญยังให้ข้อมูลที่มาจากวัตถุประสงค์เฉพาะ
เพิ่มความสำคัญในการพิจารณาด้านจริยธรรมในข้อมูลการฝึกอบรม
ด้วยความก้าวหน้าอย่างรวดเร็วของ AI ปัญหาด้านจริยธรรมหลายอย่างได้เกิดขึ้น โดยเฉพาะอย่างยิ่งในการรวบรวมข้อมูลการฝึกอบรม ข้อควรพิจารณาด้านจริยธรรมบางประการในการรวบรวมข้อมูลการฝึกอบรม ได้แก่ ความยินยอมที่ได้รับการบอกกล่าว ความโปร่งใส ความลำเอียง และความเป็นส่วนตัวของข้อมูลเนื่องจากขณะนี้ข้อมูลครอบคลุมทุกอย่างตั้งแต่ภาพใบหน้า ลายนิ้วมือ การบันทึกเสียง และข้อมูลไบโอเมตริกซ์ที่สำคัญอื่นๆ จึงกลายเป็นสิ่งสำคัญอย่างยิ่งที่จะต้องปฏิบัติตามหลักปฏิบัติทางกฎหมายและจริยธรรมเพื่อหลีกเลี่ยงการฟ้องร้องที่มีราคาแพงและความเสียหายต่อชื่อเสียง
ศักยภาพสำหรับคุณภาพที่ดียิ่งขึ้นและข้อมูลการฝึกอบรมที่หลากหลายในอนาคต
มีศักยภาพอย่างมากในการ ข้อมูลการฝึกอบรมคุณภาพสูงและหลากหลาย ในอนาคต. ด้วยความตระหนักในคุณภาพของข้อมูลและความพร้อมใช้งานของผู้ให้บริการข้อมูลที่ตอบสนองความต้องการด้านคุณภาพของโซลูชัน AI
ผู้ให้บริการข้อมูลปัจจุบันมีความเชี่ยวชาญในการใช้เทคโนโลยีที่ก้าวล้ำในการจัดหาชุดข้อมูลจำนวนมหาศาลอย่างมีจริยธรรมและถูกต้องตามกฎหมาย พวกเขายังมีทีมงานภายในเพื่อติดป้ายกำกับ ใส่คำอธิบายประกอบ และนำเสนอข้อมูลที่ปรับแต่งสำหรับโครงการ ML ต่างๆ
 ด้วยความก้าวหน้าอย่างรวดเร็วของ AI ปัญหาด้านจริยธรรมหลายอย่างได้เกิดขึ้น โดยเฉพาะอย่างยิ่งในการรวบรวมข้อมูลการฝึกอบรม ข้อควรพิจารณาด้านจริยธรรมบางประการในการรวบรวมข้อมูลการฝึกอบรม ได้แก่ ความยินยอมที่ได้รับการบอกกล่าว ความโปร่งใส ความลำเอียง และความเป็นส่วนตัวของข้อมูล
ด้วยความก้าวหน้าอย่างรวดเร็วของ AI ปัญหาด้านจริยธรรมหลายอย่างได้เกิดขึ้น โดยเฉพาะอย่างยิ่งในการรวบรวมข้อมูลการฝึกอบรม ข้อควรพิจารณาด้านจริยธรรมบางประการในการรวบรวมข้อมูลการฝึกอบรม ได้แก่ ความยินยอมที่ได้รับการบอกกล่าว ความโปร่งใส ความลำเอียง และความเป็นส่วนตัวของข้อมูลสรุป
การเป็นพันธมิตรกับผู้ขายที่เชื่อถือได้ด้วยความเข้าใจอย่างเฉียบขาดของข้อมูลและคุณภาพเป็นสิ่งสำคัญ พัฒนาโมเดล AI ระดับไฮเอนด์. Shaip เป็นบริษัทด้านคำอธิบายประกอบชั้นนำที่เชี่ยวชาญในการจัดหาโซลูชันข้อมูลแบบกำหนดเองที่ตอบสนองความต้องการและเป้าหมายโครงการ AI ของคุณ ร่วมเป็นพันธมิตรกับเราและสำรวจความสามารถ ความมุ่งมั่น และการทำงานร่วมกันที่เรานำเสนอ


