อินเทอร์เน็ตได้เปิดประตูให้ผู้คนแสดงความคิดเห็น ทัศนะ และข้อเสนอแนะอย่างเสรีเกี่ยวกับทุกสิ่งในโลกบน โซเชียลมีเดียเว็บไซต์ และบล็อก นอกจากการแสดงความคิดเห็นแล้ว ผู้คน (ลูกค้า) ยังมีอิทธิพลต่อการตัดสินใจซื้อของผู้อื่นอีกด้วย ความรู้สึกไม่ว่าจะเป็นด้านลบหรือด้านบวก มีความสำคัญต่อธุรกิจหรือแบรนด์ใดๆ ที่เกี่ยวข้องกับการขายผลิตภัณฑ์หรือบริการของตน
การช่วยให้ธุรกิจขุดความคิดเห็นเพื่อใช้ในธุรกิจคือ ประมวลผลภาษาธรรมชาติ. หนึ่งในทุก ๆ สี่ธุรกิจ มีแผนจะนำเทคโนโลยี NLP มาใช้ภายในปีหน้าเพื่อขับเคลื่อนการตัดสินใจทางธุรกิจ การใช้การวิเคราะห์ความรู้สึก NLP ช่วยให้ธุรกิจได้รับข้อมูลเชิงลึกที่ตีความได้จากข้อมูลดิบและไม่มีโครงสร้าง
การขุดความคิดเห็นหรือ การวิเคราะห์ความเชื่อมั่น เป็นเทคนิคของ NLP ที่ใช้ในการระบุความรู้สึกที่แน่นอน – บวก ลบ หรือเป็นกลาง – เชื่อมโยงกับความคิดเห็นและข้อเสนอแนะ ด้วยความช่วยเหลือของ NLP คำหลักในความคิดเห็นจะได้รับการวิเคราะห์เพื่อระบุคำที่เป็นบวกหรือลบที่อยู่ในคำหลัก
ความรู้สึกจะถูกให้คะแนนในระบบมาตราส่วนที่กำหนดคะแนนความรู้สึกให้กับอารมณ์ในข้อความ (กำหนดว่าข้อความเป็นบวกหรือลบ)
การวิเคราะห์ความรู้สึกหลายภาษาคืออะไร?

เป็นชื่อแนะนำ, การวิเคราะห์ความรู้สึกหลายภาษา เป็นเทคนิคในการทำคะแนนความรู้สึกมากกว่าหนึ่งภาษา อย่างไรก็ตาม มันไม่ง่ายอย่างนั้น วัฒนธรรม ภาษา และประสบการณ์ของเรามีอิทธิพลอย่างมากต่อพฤติกรรมและอารมณ์การซื้อของเรา หากไม่มีความเข้าใจในภาษา บริบท และวัฒนธรรมของผู้ใช้เป็นอย่างดี ก็จะไม่สามารถเข้าใจความตั้งใจ อารมณ์ และการตีความของผู้ใช้ได้อย่างถูกต้อง
ในขณะที่ระบบอัตโนมัติเป็นคำตอบสำหรับปัญหาต่างๆ ในยุคปัจจุบันของเรา การแปลด้วยเครื่อง ซอฟต์แวร์จะไม่สามารถรับความแตกต่างของภาษา ภาษาพูด ความละเอียดอ่อน และการอ้างอิงทางวัฒนธรรมในความคิดเห็นและ ความคิดเห็นต่อสินค้า มันกำลังแปล เครื่องมือ ML อาจให้คำแปลแก่คุณ แต่อาจไม่มีประโยชน์ นั่นเป็นเหตุผลที่จำเป็นต้องมีการวิเคราะห์ความรู้สึกหลายภาษา
เหตุใดจึงจำเป็นต้องมีการวิเคราะห์ความรู้สึกหลายภาษา
ธุรกิจส่วนใหญ่ใช้ภาษาอังกฤษเป็นสื่อในการสื่อสาร แต่ผู้บริโภคส่วนใหญ่ทั่วโลกไม่ได้ใช้ภาษาอังกฤษ
จากข้อมูลของ Ethnologue ประมาณ 13% ของประชากรโลกพูดภาษาอังกฤษได้ นอกจากนี้ บริติช เคานซิลระบุว่าประมาณ 25% ของประชากรโลกมีความเข้าใจภาษาอังกฤษในระดับดี หากเชื่อตัวเลขเหล่านี้ แสดงว่าผู้บริโภคส่วนใหญ่มีปฏิสัมพันธ์ระหว่างกันและธุรกิจเป็นภาษาอื่นที่ไม่ใช่ภาษาอังกฤษ
หากเป้าหมายหลักของธุรกิจคือการรักษาฐานลูกค้าให้คงอยู่และดึงดูดลูกค้าใหม่ จำเป็นต้องเข้าใจความคิดเห็นของลูกค้าที่แสดงใน ภาษาพื้นเมือง. การตรวจสอบความคิดเห็นแต่ละรายการด้วยตนเองหรือแปลเป็นภาษาอังกฤษเป็นกระบวนการที่ยุ่งยากซึ่งจะไม่ได้ผลลัพธ์ที่มีประสิทธิภาพ
ทางออกที่ยั่งยืนคือการพัฒนาหลายภาษา ระบบวิเคราะห์ความรู้สึก ที่ตรวจจับและวิเคราะห์ความคิดเห็น อารมณ์ และคำแนะนำของลูกค้าในโซเชียลมีเดีย ฟอรัม แบบสำรวจ และอื่นๆ
ขั้นตอนในการวิเคราะห์ความรู้สึกหลายภาษา
การวิเคราะห์ความรู้สึกไม่ว่าจะใช้ภาษาเดียวหรือ หลายภาษาเป็นกระบวนการที่ต้องใช้โมเดลแมชชีนเลิร์นนิง การประมวลผลภาษาธรรมชาติ และเทคนิคการวิเคราะห์ข้อมูลในการแยกข้อมูล คะแนนความรู้สึกหลายภาษา จากข้อมูล
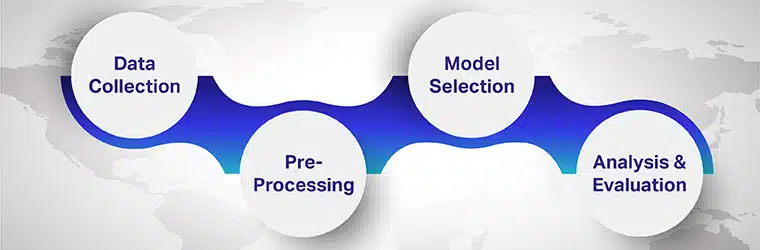
ขั้นตอนที่เกี่ยวข้องกับการวิเคราะห์ความรู้สึกหลายภาษาคือ
ขั้นตอนที่ 1: การรวบรวมข้อมูล
การรวบรวมข้อมูลเป็นขั้นตอนแรกในการใช้การวิเคราะห์ความรู้สึก เพื่อสร้างหลายภาษา โมเดลการวิเคราะห์ความรู้สึกการรับข้อมูลในภาษาต่างๆ เป็นสิ่งสำคัญ ทุกอย่างจะขึ้นอยู่กับคุณภาพของข้อมูลที่รวบรวม ใส่คำอธิบายประกอบ และติดป้ายกำกับ คุณสามารถดึงข้อมูลจาก API, ที่เก็บข้อมูลแบบโอเพ่นซอร์ส และผู้เผยแพร่
ขั้นตอนที่ 2: การประมวลผลล่วงหน้า
ควรล้างข้อมูลเว็บที่รวบรวมและรวบรวมข้อมูลจากข้อมูลนั้น ส่วนของข้อความที่ไม่สื่อความหมายเฉพาะ เช่น 'the' 'is' และอื่นๆ ควรถูกลบออก นอกจากนี้ ควรจัดกลุ่มข้อความเป็นกลุ่มคำเพื่อจัดหมวดหมู่เพื่อสื่อความหมายเชิงบวกหรือเชิงลบ
เพื่อปรับปรุงคุณภาพการจัดหมวดหมู่ เนื้อหาควรปราศจากสัญญาณรบกวน เช่น แท็ก HTML โฆษณา และสคริปต์ ภาษา คำศัพท์ และไวยากรณ์ที่ผู้คนใช้นั้นแตกต่างกันไปตามเครือข่ายสังคม สิ่งสำคัญคือต้องทำเนื้อหาดังกล่าวให้เป็นมาตรฐานและเตรียมพร้อมสำหรับการประมวลผลล่วงหน้า
อีกขั้นตอนที่สำคัญในการประมวลผลล่วงหน้าคือการใช้การประมวลผลภาษาธรรมชาติเพื่อแยกประโยค ลบคำหยุด แท็กส่วนของคำพูด แปลงคำให้เป็นรูปแบบรากของคำ และทำให้คำเป็นโทเค็นเป็นสัญลักษณ์และข้อความ
ขั้นตอนที่ 3: การเลือกรุ่น
โมเดลตามกฎ: วิธีที่ง่ายที่สุดในการวิเคราะห์ความหมายหลายภาษาคือตามกฎ อัลกอริทึมตามกฎจะทำการวิเคราะห์ตามชุดของกฎที่กำหนดไว้ล่วงหน้าซึ่งโปรแกรมโดยผู้เชี่ยวชาญ
กฎสามารถระบุคำหรือวลีที่เป็นบวกหรือลบ ตัวอย่างเช่น หากคุณเขียนรีวิวสินค้าหรือบริการ อาจมีคำที่เป็นบวกหรือลบ เช่น 'เยี่ยม' 'ช้า' 'รอ' และ 'มีประโยชน์' วิธีนี้ช่วยให้จำแนกคำได้ง่าย แต่อาจทำให้จำแนกคำที่ซับซ้อนหรือใช้ไม่บ่อยผิดได้
รุ่นอัตโนมัติ: โมเดลอัตโนมัติทำการวิเคราะห์ความรู้สึกหลายภาษาโดยไม่ต้องใช้ผู้ดูแลที่เป็นมนุษย์ แม้ว่าโมเดลแมชชีนเลิร์นนิงจะสร้างขึ้นโดยใช้ความพยายามของมนุษย์ แต่ก็สามารถทำงานได้โดยอัตโนมัติเพื่อให้ผลลัพธ์ที่แม่นยำเมื่อพัฒนาแล้ว
ข้อมูลทดสอบได้รับการวิเคราะห์ และแต่ละความคิดเห็นจะถูกระบุด้วยตนเองว่าเป็นบวกหรือลบ จากนั้นโมเดล ML จะเรียนรู้จากข้อมูลทดสอบโดยการเปรียบเทียบข้อความใหม่กับความคิดเห็นที่มีอยู่และจัดหมวดหมู่
ขั้นตอนที่ 4: การวิเคราะห์และประเมินผล
โมเดลตามกฎและแมชชีนเลิร์นนิงสามารถปรับปรุงและปรับปรุงเมื่อเวลาผ่านไปและประสบการณ์ พจนานุกรมของคำที่ใช้ไม่บ่อยหรือคะแนนสดสำหรับความคิดเห็นหลายภาษาสามารถอัปเดตเพื่อการจำแนกที่รวดเร็วและแม่นยำยิ่งขึ้น
ความท้าทายของการแปล
แปลไม่พอเหรอ? จริงไม่!
การแปลเกี่ยวข้องกับการถ่ายโอนข้อความหรือกลุ่มข้อความจากภาษาหนึ่งและค้นหาสิ่งที่เทียบเท่าในอีกภาษาหนึ่ง อย่างไรก็ตาม การแปลนั้นไม่ง่ายและไม่มีประสิทธิภาพ
นั่นเป็นเพราะมนุษย์ใช้ภาษาไม่เพียงเพื่อสื่อสารความต้องการของตนเท่านั้น แต่ยังใช้แสดงอารมณ์ด้วย นอกจากนี้ ยังมีความแตกต่างระหว่างภาษาต่างๆ เช่น อังกฤษ ฮินดี จีนกลาง และไทย เพิ่มการผสมผสานการใช้อารมณ์ คำสแลง สำนวน การประชดประชัน และอิโมจิลงในวรรณกรรมนี้ ไม่สามารถแปลข้อความได้อย่างถูกต้อง
ความท้าทายหลักบางประการของ การแปลด้วยเครื่อง เป็น
- ความส่วนตัว
- บริบท
- คำสแลงและสำนวน
- การเสียดสี
- เปรียบเทียบ
- ความเป็นกลาง
- Emojis และการใช้คำสมัยใหม่
หากไม่เข้าใจความหมายที่ถูกต้องของบทวิจารณ์ ข้อคิดเห็น และการสื่อสารเกี่ยวกับผลิตภัณฑ์ ราคา บริการ คุณลักษณะ และคุณภาพ ธุรกิจจะไม่สามารถเข้าใจความต้องการและความคิดเห็นของลูกค้าได้
การวิเคราะห์ความรู้สึกหลายภาษาเป็นกระบวนการที่ท้าทาย แต่ละภาษามีศัพท์เฉพาะ วากยสัมพันธ์ สัณฐานวิทยา และสัทวิทยาที่แตกต่างกัน เพิ่มวัฒนธรรมคำสแลง ความรู้สึกที่แสดงออกมาการเสียดสี และการเสียดสี และคุณมีปริศนาที่ท้าทายซึ่งต้องการโซลูชัน ML ที่ขับเคลื่อนด้วย AI ที่มีประสิทธิภาพ
จำเป็นต้องมีชุดข้อมูลหลายภาษาที่ครอบคลุมเพื่อพัฒนาหลายภาษาที่มีประสิทธิภาพ เครื่องมือวิเคราะห์ความรู้สึก ที่สามารถประมวลผลบทวิจารณ์และให้ข้อมูลเชิงลึกที่มีประสิทธิภาพแก่ธุรกิจ Shaip เป็นผู้นำตลาดในการจัดหาชุดข้อมูลที่มีคำอธิบายประกอบซึ่งปรับแต่งตามอุตสาหกรรม มีป้ายกำกับในหลายภาษา ซึ่งช่วยในการพัฒนาที่มีประสิทธิภาพและแม่นยำ โซลูชันการวิเคราะห์ความรู้สึกหลายภาษา.