




เสริมศักยภาพการดูแลสุขภาพด้วย Generative AI: ปฏิวัติการวินิจฉัยและการรักษา
ในช่วงไม่กี่ปีที่ผ่านมา ปัญญาประดิษฐ์ (AI) ได้สร้างความก้าวหน้าอย่างมากในอุตสาหกรรมต่างๆ และการดูแลสุขภาพก็ไม่มีข้อยกเว้น Generative AI ซึ่งเป็นส่วนย่อยของ AI ที่มุ่งเน้น
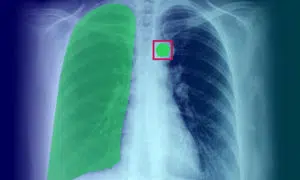
คำอธิบายประกอบรูปภาพทางการแพทย์: คำจำกัดความ การใช้งาน กรณีการใช้งาน และประเภท
คำอธิบายประกอบรูปภาพทางการแพทย์มีบทบาทสำคัญในการจัดหาข้อมูลการฝึกอบรมที่จำเป็นให้กับอัลกอริธึมการเรียนรู้ของเครื่องและโมเดล AI กระบวนการนี้เป็นสิ่งจำเป็นสำหรับ

จริยธรรมและความลำเอียง: การนำทางความท้าทายของการทำงานร่วมกันระหว่างมนุษย์และ AI ในการประเมินแบบจำลอง
ในการแสวงหาการควบคุมพลังการเปลี่ยนแปลงของปัญญาประดิษฐ์ (AI) ชุมชนเทคโนโลยีเผชิญกับความท้าทายที่สำคัญ: การรับรองความสมบูรณ์ทางจริยธรรมและลดอคติให้เหลือน้อยที่สุด

สัมผัสของมนุษย์: เสริมสร้างความคิดสร้างสรรค์ AI ด้วยการประเมินเชิงอัตนัย
ในโลกที่พัฒนาอย่างรวดเร็วของปัญญาประดิษฐ์ (AI) การแสวงหาความคิดสร้างสรรค์ไม่ได้เป็นเพียงความพยายามของมนุษย์อีกต่อไป เทคโนโลยี AI ในปัจจุบันกำลังพังทลาย

การเพิ่มความเกี่ยวข้องในการค้นหาให้สูงสุดด้วยการติดป้ายกำกับข้อมูล: เคล็ดลับและแนวทางปฏิบัติที่ดีที่สุด
ผู้ใช้ในปัจจุบันจมอยู่ในข้อมูลจำนวนมหาศาล ซึ่งทำให้การค้นหาข้อมูลที่ต้องการมีความซับซ้อน ความเกี่ยวข้องของการค้นหาจะวัดความถูกต้องของข้อมูลและ

เชื่อมช่องว่าง: บูรณาการสัญชาตญาณของมนุษย์เข้ากับการประเมินโมเดล AI
บทนำ ในยุคที่ปัญญาประดิษฐ์ (AI) กำหนดทุกแง่มุมของชีวิตของเรา การบูรณาการสัญชาตญาณของมนุษย์เข้ากับการประเมินแบบจำลอง AI เกิดขึ้น

ชุดข้อมูลการดูแลสุขภาพแบบโอเพ่นซอร์สที่ดีที่สุดสำหรับโปรเจ็กต์แมชชีนเลิร์นนิง
ระบบการดูแลสุขภาพทั่วโลกผลิตข้อมูลทางการแพทย์จำนวนมหาศาลในแต่ละวัน ซึ่งมีศักยภาพที่จะนำไปใช้กับแอปพลิเคชันการเรียนรู้ของเครื่องได้

การนำทางความเป็นส่วนตัวของข้อมูลใน AI: กลยุทธ์สำหรับการปฏิบัติตามข้อกำหนดและนวัตกรรม
บทนำ ในสภาพแวดล้อมที่พัฒนาอย่างรวดเร็วของปัญญาประดิษฐ์ (AI) บริษัทต่างๆ เช่น OpenAI กำลังเผชิญกับความท้าทายที่สำคัญในการสร้างสมดุลระหว่างความต้องการข้อมูลที่ไม่เพียงพอด้วยความเข้มงวด
อนาคตของข้อมูลด้วยการรู้จำอักขระอัจฉริยะ (ICR)
บันทึกที่เขียนด้วยลายมือมีเสน่ห์เป็นพิเศษแม้ในโลกดิจิทัลของเรา การรู้จำอักขระอัจฉริยะ (ICR) ช่วยลดการแบ่งแอนะล็อกและดิจิทัล โดยแปลงข้อความที่เขียนด้วยลายมือ

ผลกระทบของ NLP ต่อการวินิจฉัยด้านการดูแลสุขภาพ
การประมวลผลภาษาธรรมชาติ (NLP) เปลี่ยนวิธีที่เราโต้ตอบกับเทคโนโลยี โดยจะประมวลผลภาษามนุษย์เพื่อปลดล็อกศักยภาพของข้อมูลอันมหาศาล เทคโนโลยีนี้มีศักยภาพเช่นเดียวกัน

การเลือกชุดข้อมูลการรู้จำเสียงที่เหมาะสมสำหรับโมเดล AI ของคุณ
ลองนึกภาพการโต้ตอบกับ Siri หรือ Alexa ความสามารถของพวกเขาในการเข้าใจคำพูดของเรานั้นน่าทึ่งมาก ความสามารถนี้เกิดจากชุดข้อมูลที่ใช้ในการฝึกอบรม เหล่านี้

ชุดข้อมูลการดูแลสุขภาพ: ประโยชน์สำหรับ AI การดูแลสุขภาพ
ปัญญาประดิษฐ์ ซึ่งเป็นคำที่ครั้งหนึ่งเคยพบในนิยายวิทยาศาสตร์เป็นส่วนใหญ่ กลายเป็นความจริงที่ขับเคลื่อนการเติบโตของอุตสาหกรรมต่างๆ การให้คำปรึกษาด้านกลยุทธ์การย้ายครั้งต่อไป

การเรียนรู้แบบเสริมกำลังด้วยผลตอบรับของมนุษย์: ความหมายและขั้นตอน
การเรียนรู้แบบเสริมกำลัง (RL) คือการเรียนรู้ของเครื่องประเภทหนึ่ง ในแนวทางนี้ อัลกอริธึมเรียนรู้ที่จะตัดสินใจผ่านการลองผิดลองถูก เช่นเดียวกับที่มนุษย์ทำ

สาเหตุของภาพหลอน AI (และเทคนิคในการลดอาการเหล่านี้)
ภาพหลอน AI หมายถึงกรณีที่โมเดล AI โดยเฉพาะโมเดลภาษาขนาดใหญ่ (LLM) สร้างข้อมูลที่ดูเหมือนจริงแต่ไม่ถูกต้องหรือไม่เกี่ยวข้องกับ

การตรวจสอบทางคลินิกคืออะไร? คำแนะนำของคุณเกี่ยวกับแนวทางปฏิบัติและกระบวนการที่ดีที่สุด
ลองนึกถึงสถานการณ์ที่มีการพัฒนาเครื่องมือวินิจฉัยใหม่ แพทย์รู้สึกตื่นเต้นกับศักยภาพของมัน แต่ก่อนที่จะรวมเข้ากับการดูแลตามปกติ

ความสำคัญของ AI ที่มีจริยธรรม / AI ที่ยุติธรรม และประเภทของอคติที่ควรหลีกเลี่ยง
ในสาขาปัญญาประดิษฐ์ (AI) ที่กำลังเติบโต การมุ่งเน้นไปที่การพิจารณาด้านจริยธรรมและความยุติธรรมเป็นมากกว่าความจำเป็นทางศีลธรรม แต่เป็นความจำเป็นพื้นฐานสำหรับ

การสรุปเวชระเบียน AI: คำจำกัดความ ความท้าทาย และแนวทางปฏิบัติที่ดีที่สุด
การเติบโตของเวชระเบียนในอุตสาหกรรมการดูแลสุขภาพกลายเป็นทั้งความท้าทายและโอกาส ลองจินตนาการถึงโลกที่ทุกรายละเอียดอยู่ในนั้น

นามธรรมข้อมูลทางคลินิก: คำจำกัดความ กระบวนการ และอื่นๆ
โรงพยาบาลและคลินิกพบผู้ป่วยหลายพันคนในแต่ละปี สิ่งนี้ต้องการแพทย์และพยาบาลที่ทุ่มเทจำนวนมาก พวกเขาทำงานอย่างไม่เหน็ดเหนื่อยเพื่อดูแล

ข้อมูลสังเคราะห์ในการดูแลสุขภาพ: คำจำกัดความ ประโยชน์ และความท้าทาย
ลองนึกภาพสถานการณ์ที่นักวิจัยกำลังพัฒนายาตัวใหม่ พวกเขาต้องการข้อมูลผู้ป่วยที่กว้างขวางสำหรับการทดสอบ แต่มีความกังวลอย่างมากเกี่ยวกับความเป็นส่วนตัวและ

การพิจารณาของผู้เชี่ยวชาญ HIPAA สำหรับการลบการระบุตัวตน
กฎหมาย Health Insurance Portability and Accountability Act (HIPAA) กำหนดมาตรฐานในการปกป้องข้อมูลผู้ป่วยในการดูแลสุขภาพ สิ่งสำคัญในเรื่องนี้คือการไม่ระบุตัวตนที่ได้รับการป้องกัน

ผู้บุกเบิกการวิจัยด้านเนื้องอกวิทยาด้วย NLP: The Shaip Breakthrough
ดาวน์โหลดกรณีศึกษา ในภารกิจพิชิตมะเร็ง ข้อมูลมีความสำคัญพอๆ กับความมุ่งมั่น ที่ Shaip เราภูมิใจที่ได้ก้าวกระโดดครั้งใหญ่
พลังของการประมวลผลภาษาธรรมชาติ (NLP) ในรังสีวิทยา: การเพิ่มประสิทธิภาพในการวินิจฉัยและประสิทธิภาพ
รังสีวิทยามีบทบาทสำคัญในการดูแลสุขภาพ ใช้เทคนิคการถ่ายภาพ เช่น CT scan, X-rays และ MRI เพื่อวินิจฉัยและรักษาอาการต่างๆ ภาษาธรรมชาติ

บทบาทของการประมวลผลภาษาธรรมชาติ (NLP) ในด้านเนื้องอกวิทยา
มะเร็งถือเป็นความท้าทายด้านสุขภาพที่สำคัญทั่วโลก มันเกิดขึ้นเมื่อเซลล์เติบโตและแพร่กระจายในลักษณะที่ไม่สามารถควบคุมได้ เป็นสาเหตุการตายอันดับสอง

ทุกสิ่งที่คุณต้องการรู้เกี่ยวกับการเรียนรู้การเสริมกำลังจากผลตอบรับของมนุษย์
ในปี 2023 มีการนำเครื่องมือ AI เช่น ChatGPT มาใช้เพิ่มขึ้นอย่างมาก การเพิ่มขึ้นอย่างรวดเร็วนี้ทำให้เกิดการถกเถียงกันอย่างมีชีวิตชีวา และผู้คนต่างพูดคุยเกี่ยวกับประโยชน์ของ AI

พลังของ AI ในอุตสาหกรรมยานยนต์
เมื่อพูดถึงการรวม AI เข้ากับรถยนต์ โลกยืนอยู่ที่ทางแยกที่น่าทึ่ง ลองจินตนาการถึงการขับรถบนถนนที่พลุกพล่านด้วย AI ที่จะจัดการคุณ

ประโยชน์ของข้อความเป็นคำพูดในอุตสาหกรรมต่างๆ
เทคโนโลยีการแปลงข้อความเป็นคำพูด (TTS) เป็นโซลูชั่นนวัตกรรมที่แปลงข้อความที่เขียนเป็นคำพูด มันได้กลายเป็นผู้เปลี่ยนเกมในหลายอุตสาหกรรมและได้ปฏิวัติวงการ

A ถึง Z ของคำอธิบายประกอบข้อมูล
คู่มือเริ่มต้นสำหรับคำอธิบายประกอบข้อมูล: เคล็ดลับและแนวทางปฏิบัติที่ดีที่สุด คู่มือผู้ซื้อขั้นสูงสุด 2024 ตารางแนะนำดัชนี แมชชีนเลิร์นนิงคืออะไร คืออะไร

คู่มือการลบการระบุตัวตนข้อมูล: ทุกสิ่งที่มือใหม่จำเป็นต้องรู้ (ในปี 2024)
ในยุคของการเปลี่ยนแปลงทางดิจิทัล องค์กรด้านการดูแลสุขภาพกำลังเปลี่ยนการดำเนินงานไปสู่แพลตฟอร์มดิจิทัลอย่างรวดเร็ว แม้ว่าสิ่งนี้จะนำมาซึ่งประสิทธิภาพและความคล่องตัวของกระบวนการ แต่ก็เช่นกัน

AI เจนเนอเรชั่นในการดูแลสุขภาพ: การใช้งาน ข้อดี ความท้าทาย และแนวโน้มในอนาคต
การดูแลสุขภาพเป็นสาขาที่นวัตกรรมได้รับการชื่นชมและมีความสำคัญต่อการช่วยชีวิตมาโดยตลอด แม้จะมีความก้าวหน้าทางเทคโนโลยี แต่อุตสาหกรรมการดูแลสุขภาพยังคงเผชิญกับความท้าทายที่ยังคงอยู่

ความแตกต่างระหว่าง AI ที่มีความรับผิดชอบและ AI ที่มีจริยธรรม
ตลาด AI ทั่วโลกที่เติบโตอย่างรวดเร็วคาดว่าจะสูงถึง 1847 พันล้านดอลลาร์ในปี 2030 โดยที่ AI เข้ามามีบทบาทสำคัญในชีวิตของเรา โดยรู้ว่าประเภทใด



















เสริมศักยภาพการดูแลสุขภาพด้วย Generative AI: ปฏิวัติการวินิจฉัยและการรักษา
ในช่วงไม่กี่ปีที่ผ่านมา ปัญญาประดิษฐ์ (AI) ได้สร้างความก้าวหน้าอย่างมากในอุตสาหกรรมต่างๆ และการดูแลสุขภาพก็ไม่มีข้อยกเว้น Generative AI ซึ่งเป็นส่วนย่อยของ AI ที่มุ่งเน้น
คำอธิบายประกอบรูปภาพทางการแพทย์: คำจำกัดความ การใช้งาน กรณีการใช้งาน และประเภท
คำอธิบายประกอบรูปภาพทางการแพทย์มีบทบาทสำคัญในการจัดหาข้อมูลการฝึกอบรมที่จำเป็นให้กับอัลกอริธึมการเรียนรู้ของเครื่องและโมเดล AI กระบวนการนี้เป็นสิ่งจำเป็นสำหรับ
จริยธรรมและความลำเอียง: การนำทางความท้าทายของการทำงานร่วมกันระหว่างมนุษย์และ AI ในการประเมินแบบจำลอง
ในการแสวงหาการควบคุมพลังการเปลี่ยนแปลงของปัญญาประดิษฐ์ (AI) ชุมชนเทคโนโลยีเผชิญกับความท้าทายที่สำคัญ: การรับรองความสมบูรณ์ทางจริยธรรมและลดอคติให้เหลือน้อยที่สุด
สัมผัสของมนุษย์: เสริมสร้างความคิดสร้างสรรค์ AI ด้วยการประเมินเชิงอัตนัย
ในโลกที่พัฒนาอย่างรวดเร็วของปัญญาประดิษฐ์ (AI) การแสวงหาความคิดสร้างสรรค์ไม่ได้เป็นเพียงความพยายามของมนุษย์อีกต่อไป เทคโนโลยี AI ในปัจจุบันกำลังพังทลาย
การเพิ่มความเกี่ยวข้องในการค้นหาให้สูงสุดด้วยการติดป้ายกำกับข้อมูล: เคล็ดลับและแนวทางปฏิบัติที่ดีที่สุด
ผู้ใช้ในปัจจุบันจมอยู่ในข้อมูลจำนวนมหาศาล ซึ่งทำให้การค้นหาข้อมูลที่ต้องการมีความซับซ้อน ความเกี่ยวข้องของการค้นหาจะวัดความถูกต้องของข้อมูลและ
เชื่อมช่องว่าง: บูรณาการสัญชาตญาณของมนุษย์เข้ากับการประเมินโมเดล AI
บทนำ ในยุคที่ปัญญาประดิษฐ์ (AI) กำหนดทุกแง่มุมของชีวิตของเรา การบูรณาการสัญชาตญาณของมนุษย์เข้ากับการประเมินแบบจำลอง AI เกิดขึ้น
ชุดข้อมูลการดูแลสุขภาพแบบโอเพ่นซอร์สที่ดีที่สุดสำหรับโปรเจ็กต์แมชชีนเลิร์นนิง
ระบบการดูแลสุขภาพทั่วโลกผลิตข้อมูลทางการแพทย์จำนวนมหาศาลในแต่ละวัน ซึ่งมีศักยภาพที่จะนำไปใช้กับแอปพลิเคชันการเรียนรู้ของเครื่องได้
การนำทางความเป็นส่วนตัวของข้อมูลใน AI: กลยุทธ์สำหรับการปฏิบัติตามข้อกำหนดและนวัตกรรม
บทนำ ในสภาพแวดล้อมที่พัฒนาอย่างรวดเร็วของปัญญาประดิษฐ์ (AI) บริษัทต่างๆ เช่น OpenAI กำลังเผชิญกับความท้าทายที่สำคัญในการสร้างสมดุลระหว่างความต้องการข้อมูลที่ไม่เพียงพอด้วยความเข้มงวด
อนาคตของข้อมูลด้วยการรู้จำอักขระอัจฉริยะ (ICR)
บันทึกที่เขียนด้วยลายมือมีเสน่ห์เป็นพิเศษแม้ในโลกดิจิทัลของเรา การรู้จำอักขระอัจฉริยะ (ICR) ช่วยลดการแบ่งแอนะล็อกและดิจิทัล โดยแปลงข้อความที่เขียนด้วยลายมือ
ผลกระทบของ NLP ต่อการวินิจฉัยด้านการดูแลสุขภาพ
การประมวลผลภาษาธรรมชาติ (NLP) เปลี่ยนวิธีที่เราโต้ตอบกับเทคโนโลยี โดยจะประมวลผลภาษามนุษย์เพื่อปลดล็อกศักยภาพของข้อมูลอันมหาศาล เทคโนโลยีนี้มีศักยภาพเช่นเดียวกัน
การเลือกชุดข้อมูลการรู้จำเสียงที่เหมาะสมสำหรับโมเดล AI ของคุณ
ลองนึกภาพการโต้ตอบกับ Siri หรือ Alexa ความสามารถของพวกเขาในการเข้าใจคำพูดของเรานั้นน่าทึ่งมาก ความสามารถนี้เกิดจากชุดข้อมูลที่ใช้ในการฝึกอบรม เหล่านี้
ชุดข้อมูลการดูแลสุขภาพ: ประโยชน์สำหรับ AI การดูแลสุขภาพ
ปัญญาประดิษฐ์ ซึ่งเป็นคำที่ครั้งหนึ่งเคยพบในนิยายวิทยาศาสตร์เป็นส่วนใหญ่ กลายเป็นความจริงที่ขับเคลื่อนการเติบโตของอุตสาหกรรมต่างๆ การให้คำปรึกษาด้านกลยุทธ์การย้ายครั้งต่อไป
การเรียนรู้แบบเสริมกำลังด้วยผลตอบรับของมนุษย์: ความหมายและขั้นตอน
การเรียนรู้แบบเสริมกำลัง (RL) คือการเรียนรู้ของเครื่องประเภทหนึ่ง ในแนวทางนี้ อัลกอริธึมเรียนรู้ที่จะตัดสินใจผ่านการลองผิดลองถูก เช่นเดียวกับที่มนุษย์ทำ
สาเหตุของภาพหลอน AI (และเทคนิคในการลดอาการเหล่านี้)
ภาพหลอน AI หมายถึงกรณีที่โมเดล AI โดยเฉพาะโมเดลภาษาขนาดใหญ่ (LLM) สร้างข้อมูลที่ดูเหมือนจริงแต่ไม่ถูกต้องหรือไม่เกี่ยวข้องกับ
การตรวจสอบทางคลินิกคืออะไร? คำแนะนำของคุณเกี่ยวกับแนวทางปฏิบัติและกระบวนการที่ดีที่สุด
ลองนึกถึงสถานการณ์ที่มีการพัฒนาเครื่องมือวินิจฉัยใหม่ แพทย์รู้สึกตื่นเต้นกับศักยภาพของมัน แต่ก่อนที่จะรวมเข้ากับการดูแลตามปกติ
ความสำคัญของ AI ที่มีจริยธรรม / AI ที่ยุติธรรม และประเภทของอคติที่ควรหลีกเลี่ยง
ในสาขาปัญญาประดิษฐ์ (AI) ที่กำลังเติบโต การมุ่งเน้นไปที่การพิจารณาด้านจริยธรรมและความยุติธรรมเป็นมากกว่าความจำเป็นทางศีลธรรม แต่เป็นความจำเป็นพื้นฐานสำหรับ
การสรุปเวชระเบียน AI: คำจำกัดความ ความท้าทาย และแนวทางปฏิบัติที่ดีที่สุด
การเติบโตของเวชระเบียนในอุตสาหกรรมการดูแลสุขภาพกลายเป็นทั้งความท้าทายและโอกาส ลองจินตนาการถึงโลกที่ทุกรายละเอียดอยู่ในนั้น
นามธรรมข้อมูลทางคลินิก: คำจำกัดความ กระบวนการ และอื่นๆ
โรงพยาบาลและคลินิกพบผู้ป่วยหลายพันคนในแต่ละปี สิ่งนี้ต้องการแพทย์และพยาบาลที่ทุ่มเทจำนวนมาก พวกเขาทำงานอย่างไม่เหน็ดเหนื่อยเพื่อดูแล
ข้อมูลสังเคราะห์ในการดูแลสุขภาพ: คำจำกัดความ ประโยชน์ และความท้าทาย
ลองนึกภาพสถานการณ์ที่นักวิจัยกำลังพัฒนายาตัวใหม่ พวกเขาต้องการข้อมูลผู้ป่วยที่กว้างขวางสำหรับการทดสอบ แต่มีความกังวลอย่างมากเกี่ยวกับความเป็นส่วนตัวและ
การพิจารณาของผู้เชี่ยวชาญ HIPAA สำหรับการลบการระบุตัวตน
กฎหมาย Health Insurance Portability and Accountability Act (HIPAA) กำหนดมาตรฐานในการปกป้องข้อมูลผู้ป่วยในการดูแลสุขภาพ สิ่งสำคัญในเรื่องนี้คือการไม่ระบุตัวตนที่ได้รับการป้องกัน
ผู้บุกเบิกการวิจัยด้านเนื้องอกวิทยาด้วย NLP: The Shaip Breakthrough
ดาวน์โหลดกรณีศึกษา ในภารกิจพิชิตมะเร็ง ข้อมูลมีความสำคัญพอๆ กับความมุ่งมั่น ที่ Shaip เราภูมิใจที่ได้ก้าวกระโดดครั้งใหญ่
พลังของการประมวลผลภาษาธรรมชาติ (NLP) ในรังสีวิทยา: การเพิ่มประสิทธิภาพในการวินิจฉัยและประสิทธิภาพ
รังสีวิทยามีบทบาทสำคัญในการดูแลสุขภาพ ใช้เทคนิคการถ่ายภาพ เช่น CT scan, X-rays และ MRI เพื่อวินิจฉัยและรักษาอาการต่างๆ ภาษาธรรมชาติ
บทบาทของการประมวลผลภาษาธรรมชาติ (NLP) ในด้านเนื้องอกวิทยา
มะเร็งถือเป็นความท้าทายด้านสุขภาพที่สำคัญทั่วโลก มันเกิดขึ้นเมื่อเซลล์เติบโตและแพร่กระจายในลักษณะที่ไม่สามารถควบคุมได้ เป็นสาเหตุการตายอันดับสอง
ทุกสิ่งที่คุณต้องการรู้เกี่ยวกับการเรียนรู้การเสริมกำลังจากผลตอบรับของมนุษย์
ในปี 2023 มีการนำเครื่องมือ AI เช่น ChatGPT มาใช้เพิ่มขึ้นอย่างมาก การเพิ่มขึ้นอย่างรวดเร็วนี้ทำให้เกิดการถกเถียงกันอย่างมีชีวิตชีวา และผู้คนต่างพูดคุยเกี่ยวกับประโยชน์ของ AI
พลังของ AI ในอุตสาหกรรมยานยนต์
เมื่อพูดถึงการรวม AI เข้ากับรถยนต์ โลกยืนอยู่ที่ทางแยกที่น่าทึ่ง ลองจินตนาการถึงการขับรถบนถนนที่พลุกพล่านด้วย AI ที่จะจัดการคุณ
ประโยชน์ของข้อความเป็นคำพูดในอุตสาหกรรมต่างๆ
เทคโนโลยีการแปลงข้อความเป็นคำพูด (TTS) เป็นโซลูชั่นนวัตกรรมที่แปลงข้อความที่เขียนเป็นคำพูด มันได้กลายเป็นผู้เปลี่ยนเกมในหลายอุตสาหกรรมและได้ปฏิวัติวงการ
A ถึง Z ของคำอธิบายประกอบข้อมูล
คู่มือเริ่มต้นสำหรับคำอธิบายประกอบข้อมูล: เคล็ดลับและแนวทางปฏิบัติที่ดีที่สุด คู่มือผู้ซื้อขั้นสูงสุด 2024 ตารางแนะนำดัชนี แมชชีนเลิร์นนิงคืออะไร คืออะไร
คู่มือการลบการระบุตัวตนข้อมูล: ทุกสิ่งที่มือใหม่จำเป็นต้องรู้ (ในปี 2024)
ในยุคของการเปลี่ยนแปลงทางดิจิทัล องค์กรด้านการดูแลสุขภาพกำลังเปลี่ยนการดำเนินงานไปสู่แพลตฟอร์มดิจิทัลอย่างรวดเร็ว แม้ว่าสิ่งนี้จะนำมาซึ่งประสิทธิภาพและความคล่องตัวของกระบวนการ แต่ก็เช่นกัน
AI เจนเนอเรชั่นในการดูแลสุขภาพ: การใช้งาน ข้อดี ความท้าทาย และแนวโน้มในอนาคต
การดูแลสุขภาพเป็นสาขาที่นวัตกรรมได้รับการชื่นชมและมีความสำคัญต่อการช่วยชีวิตมาโดยตลอด แม้จะมีความก้าวหน้าทางเทคโนโลยี แต่อุตสาหกรรมการดูแลสุขภาพยังคงเผชิญกับความท้าทายที่ยังคงอยู่
ความแตกต่างระหว่าง AI ที่มีความรับผิดชอบและ AI ที่มีจริยธรรม
ตลาด AI ทั่วโลกที่เติบโตอย่างรวดเร็วคาดว่าจะสูงถึง 1847 พันล้านดอลลาร์ในปี 2030 โดยที่ AI เข้ามามีบทบาทสำคัญในชีวิตของเรา โดยรู้ว่าประเภทใด

NLP คืออะไร? วิธีการทำงาน ประโยชน์ ความท้าทาย ตัวอย่าง
ดาวน์โหลดอินโฟกราฟิก NLP คืออะไร? Natural Language Processing (NLP) เป็นสาขาย่อยของปัญญาประดิษฐ์ (AI) ช่วยให้หุ่นยนต์วิเคราะห์และเข้าใจภาษามนุษย์

OCR – คำจำกัดความ ประโยชน์ ความท้าทาย และกรณีการใช้งาน [อินโฟกราฟิก]
OCR เป็นเทคโนโลยีที่ช่วยให้เครื่องสามารถอ่านข้อความและภาพที่พิมพ์ได้ มักใช้ในแอปพลิเคชันทางธุรกิจ เช่น การแปลงเอกสารเป็นดิจิทัลสำหรับการจัดเก็บหรือการประมวลผล และในแอปพลิเคชันสำหรับผู้บริโภค เช่น การสแกนใบเสร็จเพื่อขอเบิกค่าใช้จ่าย

สถานะของการสนทนา AI 2022
The State of Conversational AI 2022 AI สนทนาคืออะไร? วิธีการแบบเป็นโปรแกรมและชาญฉลาดในการนำเสนอประสบการณ์การสนทนา เลียนแบบการสนทนากับคนจริง ผ่านดิจิทัลและโทรคมนาคม

การเก็บรวบรวมข้อมูลคืออะไร? ทุกสิ่งที่มือใหม่ต้องรู้
โมเดล #AI/ #ML ที่ชาญฉลาดมีอยู่ทั่วไป ไม่ว่าจะเป็นแบบจำลองการดูแลสุขภาพเชิงพยากรณ์ การวินิจฉัยเชิงรุก

การติดฉลากข้อมูลคืออะไร? ทุกสิ่งที่มือใหม่ต้องรู้
ดาวน์โหลดโมเดล Infographics Intelligent AI จำเป็นต้องได้รับการฝึกอบรมอย่างกว้างขวางเพื่อให้สามารถระบุรูปแบบ วัตถุ และตัดสินใจได้อย่างน่าเชื่อถือในที่สุด อย่างไรก็ตาม การอบรม