

โมเดลภาษาขนาดใหญ่คืออะไร
โมเดลภาษาขนาดใหญ่ (LLM) คือระบบปัญญาประดิษฐ์ (AI) ขั้นสูงที่ออกแบบมาเพื่อประมวลผล ทำความเข้าใจ และสร้างข้อความที่เหมือนมนุษย์ พวกมันใช้เทคนิคการเรียนรู้เชิงลึกและฝึกฝนบนชุดข้อมูลขนาดใหญ่ ซึ่งมักจะประกอบด้วยคำศัพท์หลายพันล้านคำจากแหล่งต่างๆ เช่น เว็บไซต์ หนังสือ และบทความ การฝึกอบรมที่ครอบคลุมนี้ช่วยให้ LLM สามารถเข้าใจความแตกต่างของภาษา ไวยากรณ์ บริบท และแม้แต่ความรู้ทั่วไปบางแง่มุม
LLM ยอดนิยมบางรายการ เช่น GPT-3 ของ OpenAI ใช้โครงข่ายประสาทเทียมประเภทหนึ่งที่เรียกว่าทรานส์ฟอร์มเมอร์ ซึ่งช่วยให้จัดการงานภาษาที่ซับซ้อนด้วยความสามารถที่โดดเด่น โมเดลเหล่านี้สามารถทำงานได้หลากหลาย เช่น:
- ตอบคำถาม
- ข้อความสรุป
- การแปลภาษา
- การสร้างเนื้อหา
- แม้กระทั่งการมีส่วนร่วมในการสนทนาแบบโต้ตอบกับผู้ใช้
ในขณะที่ LLM มีการพัฒนาอย่างต่อเนื่อง พวกเขามีศักยภาพที่ดีในการปรับปรุงและทำให้แอปพลิเคชันต่างๆ เป็นอัตโนมัติในอุตสาหกรรมต่างๆ ตั้งแต่การบริการลูกค้าและการสร้างเนื้อหาไปจนถึงการศึกษาและการวิจัย อย่างไรก็ตาม พวกเขายังหยิบยกข้อกังวลด้านจริยธรรมและสังคม เช่น พฤติกรรมที่มีอคติหรือการใช้งานในทางที่ผิด ซึ่งจำเป็นต้องได้รับการแก้ไขเนื่องจากความก้าวหน้าทางเทคโนโลยี

ตัวอย่างยอดนิยมของโมเดลภาษาขนาดใหญ่
ต่อไปนี้คือตัวอย่างที่โดดเด่นบางประการของ LLM ที่ใช้กันอย่างแพร่หลายในอุตสาหกรรมประเภทต่างๆ:
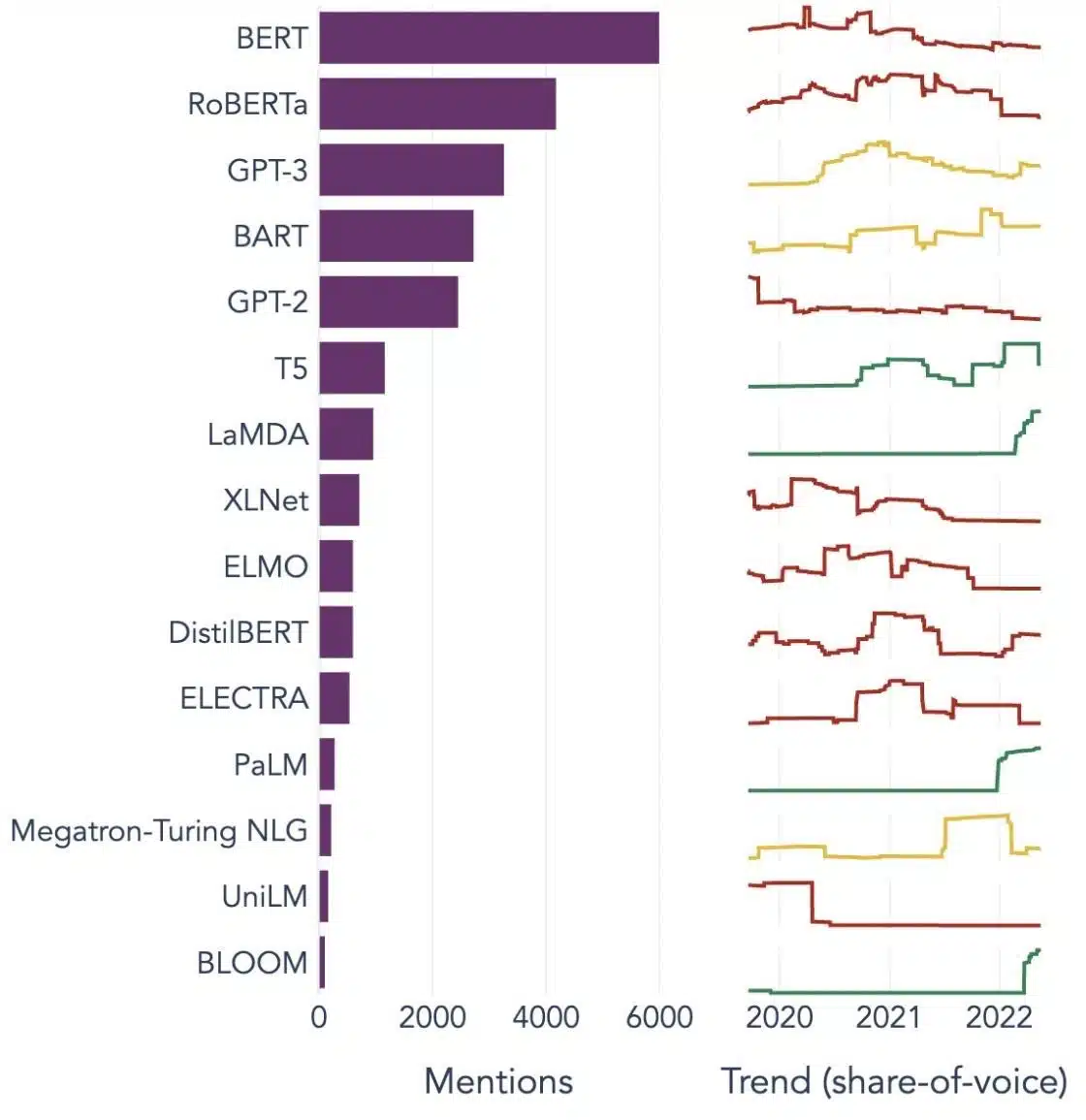
แหล่งที่มาของภาพ: สู่วิทยาศาสตร์ข้อมูล
โมเดล LLM ได้รับการฝึกฝนอย่างไร
การฝึกอบรมโมเดลภาษาขนาดใหญ่ (LLM) เป็นความสำเร็จที่เกี่ยวข้องกับขั้นตอนที่สำคัญหลายขั้นตอน ต่อไปนี้เป็นขั้นตอนง่ายๆ ทีละขั้นตอนของกระบวนการ:
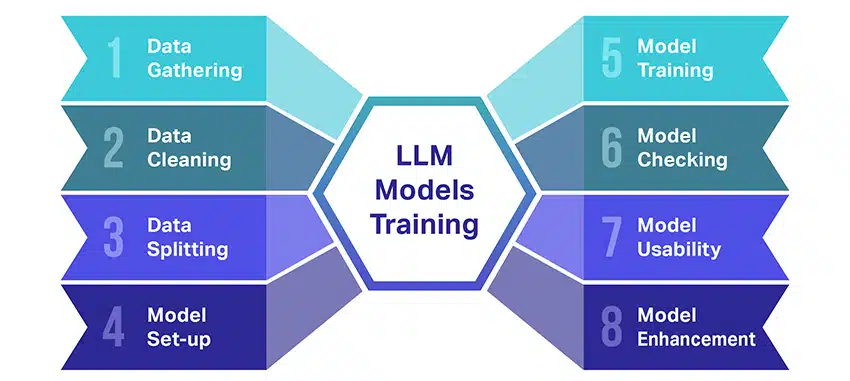
- การรวบรวมข้อมูลข้อความ: การฝึกอบรม LLM เริ่มต้นด้วยการรวบรวมข้อมูลข้อความจำนวนมหาศาล ข้อมูลนี้อาจมาจากหนังสือ เว็บไซต์ บทความ หรือแพลตฟอร์มโซเชียลมีเดีย จุดมุ่งหมายคือการจับภาพความหลากหลายของภาษามนุษย์
- การล้างข้อมูล: ข้อมูลที่เป็นข้อความดิบจะถูกจัดระเบียบในกระบวนการที่เรียกว่าการประมวลผลล่วงหน้า ซึ่งรวมถึงงานต่างๆ เช่น การลบอักขระที่ไม่ต้องการ การแยกข้อความออกเป็นส่วนเล็กๆ ที่เรียกว่าโทเค็น และทำให้ทั้งหมดอยู่ในรูปแบบที่โมเดลสามารถทำงานได้
- แยกข้อมูล: ถัดไป ข้อมูลที่สะอาดจะถูกแบ่งออกเป็นสองชุด ข้อมูลการฝึกอบรมหนึ่งชุดจะถูกใช้เพื่อฝึกอบรมโมเดล ส่วนอีกชุดคือข้อมูลการตรวจสอบ จะใช้ในภายหลังเพื่อทดสอบประสิทธิภาพของโมเดล
- การตั้งค่าโมเดล: จากนั้นจะมีการกำหนดโครงสร้างของ LLM หรือที่เรียกว่าสถาปัตยกรรม สิ่งนี้เกี่ยวข้องกับการเลือกประเภทของโครงข่ายประสาทเทียมและตัดสินใจเลือกพารามิเตอร์ต่างๆ เช่น จำนวนเลเยอร์และหน่วยที่ซ่อนอยู่ภายในเครือข่าย
- การฝึกอบรมโมเดล: การฝึกจริงเริ่มต้นขึ้นแล้ว แบบจำลอง LLM เรียนรู้โดยดูที่ข้อมูลการฝึกอบรม ทำการคาดคะเนตามสิ่งที่ได้เรียนรู้จนถึงตอนนี้ จากนั้นปรับพารามิเตอร์ภายในเพื่อลดความแตกต่างระหว่างการคาดคะเนและข้อมูลจริง
- การตรวจสอบรุ่น: การเรียนรู้ของโมเดล LLM ได้รับการตรวจสอบโดยใช้ข้อมูลการตรวจสอบ สิ่งนี้ช่วยให้เห็นว่าโมเดลทำงานได้ดีเพียงใดและปรับแต่งการตั้งค่าของโมเดลเพื่อประสิทธิภาพที่ดีขึ้น
- การใช้โมเดล: หลังจากอบรมและประเมินผลแล้ว โมเดล LLM ก็พร้อมใช้งาน ตอนนี้สามารถรวมเข้ากับแอปพลิเคชันหรือระบบที่จะสร้างข้อความตามอินพุตใหม่ที่ได้รับ
- การปรับปรุงโมเดล: สุดท้ายนี้ ยังมีที่ว่างสำหรับการปรับปรุงอยู่เสมอ โมเดล LLM สามารถปรับแต่งเพิ่มเติมเมื่อเวลาผ่านไป โดยใช้ข้อมูลที่อัปเดตหรือปรับการตั้งค่าตามความคิดเห็นและการใช้งานจริง
โปรดจำไว้ว่ากระบวนการนี้ต้องการทรัพยากรด้านการคำนวณที่สำคัญ เช่น หน่วยประมวลผลที่ทรงพลังและพื้นที่เก็บข้อมูลขนาดใหญ่ ตลอดจนความรู้เฉพาะทางในการเรียนรู้ของเครื่อง นั่นเป็นเหตุผลที่มักจะดำเนินการโดยองค์กรหรือบริษัทวิจัยเฉพาะที่สามารถเข้าถึงโครงสร้างพื้นฐานและความเชี่ยวชาญที่จำเป็นได้
LLM พึ่งพาการเรียนรู้ภายใต้การดูแลหรือไม่มีผู้ดูแลหรือไม่?
แบบจำลองภาษาขนาดใหญ่มักได้รับการฝึกฝนโดยใช้วิธีการที่เรียกว่าการเรียนรู้แบบมีผู้สอน พูดง่ายๆ ก็คือ พวกเขาเรียนรู้จากตัวอย่างที่แสดงคำตอบที่ถูกต้อง
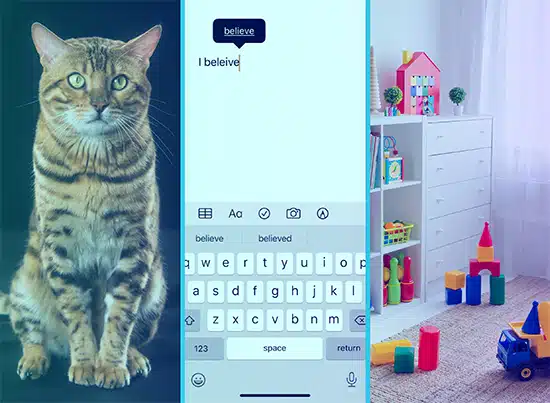 จินตนาการว่าคุณกำลังสอนคำศัพท์ให้เด็กโดยแสดงรูปภาพให้พวกเขาดู คุณให้พวกเขาดูรูปแมวและพูดว่า "แมว" และพวกเขาเรียนรู้ที่จะเชื่อมโยงรูปภาพนั้นกับคำนั้น นั่นคือวิธีการทำงานของการเรียนรู้แบบมีผู้สอน โมเดลได้รับข้อความจำนวนมาก ("รูปภาพ") และผลลัพธ์ที่สอดคล้องกัน ("คำ") และเรียนรู้ที่จะจับคู่พวกมัน
จินตนาการว่าคุณกำลังสอนคำศัพท์ให้เด็กโดยแสดงรูปภาพให้พวกเขาดู คุณให้พวกเขาดูรูปแมวและพูดว่า "แมว" และพวกเขาเรียนรู้ที่จะเชื่อมโยงรูปภาพนั้นกับคำนั้น นั่นคือวิธีการทำงานของการเรียนรู้แบบมีผู้สอน โมเดลได้รับข้อความจำนวนมาก ("รูปภาพ") และผลลัพธ์ที่สอดคล้องกัน ("คำ") และเรียนรู้ที่จะจับคู่พวกมัน
ดังนั้น หากคุณป้อน LLM หนึ่งประโยค ระบบจะพยายามคาดเดาคำหรือวลีถัดไปตามสิ่งที่ได้เรียนรู้จากตัวอย่าง ด้วยวิธีนี้ ระบบจะเรียนรู้วิธีสร้างข้อความที่เหมาะสมและเหมาะสมกับบริบท
ที่กล่าวว่า บางครั้ง LLM ก็ใช้การเรียนรู้แบบไม่มีผู้ดูแลเช่นกัน สิ่งนี้เหมือนกับการปล่อยให้เด็กสำรวจห้องที่เต็มไปด้วยของเล่นต่างๆ และเรียนรู้เกี่ยวกับพวกเขาด้วยตัวเอง โมเดลจะดูข้อมูลที่ไม่มีป้ายกำกับ รูปแบบการเรียนรู้ และโครงสร้างโดยไม่ได้รับคำตอบที่ "ถูกต้อง"
การเรียนรู้ภายใต้การดูแลจะใช้ข้อมูลที่มีป้ายกำกับว่าอินพุตและเอาต์พุต ตรงกันข้ามกับการเรียนรู้แบบไม่มีผู้ดูแล ซึ่งไม่ได้ใช้ข้อมูลเอาต์พุตที่มีป้ายกำกับ
กล่าวโดยสรุป LLMs ส่วนใหญ่ได้รับการฝึกฝนโดยใช้การเรียนรู้แบบมีผู้สอน แต่ก็ยังสามารถใช้การเรียนรู้แบบไม่มีผู้ดูแลเพื่อเพิ่มขีดความสามารถ เช่น สำหรับการวิเคราะห์เชิงสำรวจและการลดมิติข้อมูล
ปริมาณข้อมูล (หน่วยเป็น GB) ที่จำเป็นในการฝึกโมเดลภาษาขนาดใหญ่คืออะไร
โลกแห่งความเป็นไปได้สำหรับการรู้จำข้อมูลเสียงพูดและแอปพลิเคชั่นเสียงนั้นใหญ่โต และมีการใช้ในหลายอุตสาหกรรมสำหรับแอพพลิเคชั่นมากมาย
การฝึกโมเดลภาษาขนาดใหญ่ไม่ใช่กระบวนการเดียวที่เหมาะกับทุกคน โดยเฉพาะอย่างยิ่งเมื่อเป็นเรื่องของข้อมูลที่จำเป็น ขึ้นอยู่กับหลายสิ่ง:
- การออกแบบโมเดล
- ต้องทำอาชีพอะไร?
- ประเภทของข้อมูลที่คุณกำลังใช้
- คุณต้องการให้ทำงานได้ดีแค่ไหน?
ที่กล่าวว่า LLM การฝึกอบรมมักจะต้องใช้ข้อมูลข้อความจำนวนมาก แต่เรากำลังพูดถึงเรื่องใหญ่แค่ไหน? คิดไปไกลกว่ากิกะไบต์ (GB) เรามักจะดูที่ข้อมูลขนาดเทราไบต์ (TB) หรือแม้แต่เพตะไบต์ (PB)
พิจารณา GPT-3 ซึ่งเป็นหนึ่งใน LLM ที่ใหญ่ที่สุด มีการฝึกอบรมเกี่ยวกับ ข้อมูลข้อความ 570 GB. LLM ที่เล็กกว่าอาจต้องการน้อยกว่า - อาจจะ 10-20 GB หรือแม้แต่ 1 GB ของกิกะไบต์ - แต่ก็ยังมากอยู่

แต่ไม่ใช่แค่ขนาดของข้อมูลเท่านั้น เรื่องคุณภาพก็เช่นกัน ข้อมูลต้องสะอาดและหลากหลายเพื่อช่วยให้โมเดลเรียนรู้ได้อย่างมีประสิทธิภาพ และคุณไม่สามารถลืมชิ้นส่วนสำคัญอื่นๆ ของปริศนาได้ เช่น พลังการประมวลผลที่คุณต้องการ อัลกอริทึมที่คุณใช้สำหรับการฝึกอบรม และการตั้งค่าฮาร์ดแวร์ที่คุณมี ปัจจัยทั้งหมดเหล่านี้มีส่วนสำคัญในการฝึกอบรม LLM
การเพิ่มขึ้นของโมเดลภาษาขนาดใหญ่: เหตุใดจึงมีความสำคัญ
LLMs ไม่ใช่แค่แนวคิดหรือการทดลองอีกต่อไป พวกเขากำลังมีบทบาทสำคัญในภูมิทัศน์ดิจิทัลของเรามากขึ้นเรื่อยๆ แต่ทำไมสิ่งนี้ถึงเกิดขึ้น? อะไรทำให้ LLM เหล่านี้มีความสำคัญมาก เรามาเจาะลึกถึงปัจจัยสำคัญบางประการกัน
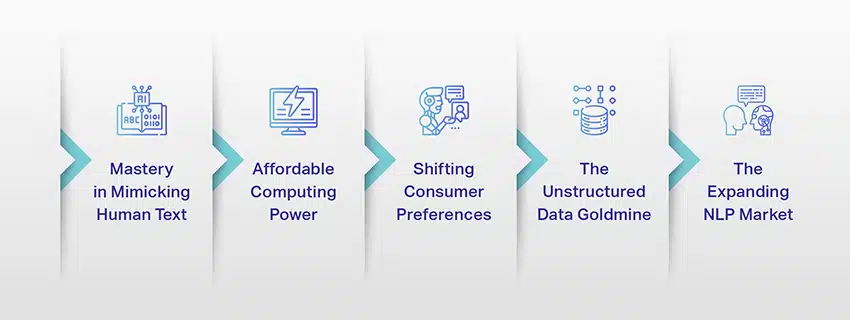
เชี่ยวชาญในการเลียนแบบข้อความของมนุษย์
LLM ได้เปลี่ยนวิธีที่เราจัดการกับงานที่ใช้ภาษา แบบจำลองเหล่านี้สร้างขึ้นโดยใช้อัลกอริธึมการเรียนรู้ของเครื่องที่แข็งแกร่ง มาพร้อมกับความสามารถในการเข้าใจความแตกต่างของภาษามนุษย์ รวมถึงบริบท อารมณ์ และแม้แต่การเสียดสีในระดับหนึ่ง ความสามารถในการเลียนแบบภาษามนุษย์นี้ไม่ได้เป็นเพียงสิ่งแปลกใหม่ แต่มีนัยยะสำคัญ
ความสามารถในการสร้างข้อความขั้นสูงของ LLM สามารถปรับปรุงทุกอย่างตั้งแต่การสร้างเนื้อหาไปจนถึงการโต้ตอบกับฝ่ายบริการลูกค้า
ลองนึกภาพว่าสามารถถามคำถามที่ซับซ้อนกับผู้ช่วยดิจิทัลและได้คำตอบที่ไม่เพียงสมเหตุสมผล แต่ยังสอดคล้องกัน ตรงประเด็น และแสดงออกมาในโทนเสียงสนทนาอีกด้วย นั่นคือสิ่งที่ LLM เปิดใช้งาน พวกเขากำลังกระตุ้นการโต้ตอบระหว่างมนุษย์กับเครื่องจักรที่เป็นธรรมชาติและมีส่วนร่วมมากขึ้น ยกระดับประสบการณ์ผู้ใช้ และทำให้การเข้าถึงข้อมูลเป็นประชาธิปไตย
พลังคอมพิวเตอร์ราคาไม่แพง
การเพิ่มขึ้นของ LLM จะไม่สามารถเกิดขึ้นได้หากไม่มีการพัฒนาแบบคู่ขนานในด้านคอมพิวเตอร์ โดยเฉพาะอย่างยิ่ง การทำให้เป็นประชาธิปไตยของทรัพยากรการคำนวณมีบทบาทสำคัญในวิวัฒนาการและการนำ LLMs มาใช้
แพลตฟอร์มบนคลาวด์นำเสนอการเข้าถึงทรัพยากรการประมวลผลประสิทธิภาพสูงอย่างที่ไม่เคยมีมาก่อน ด้วยวิธีนี้ แม้แต่องค์กรขนาดเล็กและนักวิจัยอิสระก็สามารถฝึกฝนโมเดลแมชชีนเลิร์นนิงที่ซับซ้อนได้
นอกจากนี้ การปรับปรุงในหน่วยประมวลผล (เช่น GPU และ TPU) เมื่อรวมกับการเพิ่มขึ้นของการประมวลผลแบบกระจาย ทำให้สามารถฝึกโมเดลที่มีพารามิเตอร์หลายพันล้านตัวได้ ความสามารถในการเข้าถึงที่เพิ่มขึ้นของพลังการประมวลผลช่วยให้ LLMs เติบโตและประสบความสำเร็จ ซึ่งนำไปสู่นวัตกรรมและแอปพลิเคชันเพิ่มเติมในสาขานี้
การเปลี่ยนแปลงความชอบของผู้บริโภค
ผู้บริโภคในปัจจุบันไม่เพียงแค่ต้องการคำตอบเท่านั้น พวกเขาต้องการปฏิสัมพันธ์ที่มีส่วนร่วมและสัมพันธ์กัน ในขณะที่ผู้คนเติบโตขึ้นมาโดยใช้เทคโนโลยีดิจิทัล เห็นได้ชัดว่าความต้องการเทคโนโลยีที่ให้ความรู้สึกเป็นธรรมชาติและเหมือนมนุษย์เพิ่มมากขึ้น LLM เสนอโอกาสที่ไม่มีใครเทียบได้เพื่อตอบสนองความคาดหวังเหล่านี้ โดยการสร้างข้อความเหมือนมนุษย์ โมเดลเหล่านี้สามารถสร้างประสบการณ์ดิจิทัลที่น่าดึงดูดและไดนามิก ซึ่งสามารถเพิ่มความพึงพอใจและความภักดีของผู้ใช้ได้ ไม่ว่าจะเป็นแชทบอท AI ที่ให้บริการลูกค้าหรือผู้ช่วยเสียงที่แจ้งข่าวสารล่าสุด LLM กำลังนำเข้าสู่ยุคของ AI ที่เข้าใจเรามากขึ้น
Goldmine ข้อมูลที่ไม่มีโครงสร้าง
ข้อมูลที่ไม่มีโครงสร้าง เช่น อีเมล โพสต์บนโซเชียลมีเดีย และบทวิจารณ์ของลูกค้า คือขุมทรัพย์แห่งข้อมูลเชิงลึก ก็ประมาณว่าจบ ลด 80% ของข้อมูลองค์กรไม่มีโครงสร้างและเติบโตในอัตรา ลด 55% ต่อปี. ข้อมูลนี้เป็นเหมืองทองคำสำหรับธุรกิจหากมีการใช้ประโยชน์อย่างเหมาะสม
LLM เข้ามามีบทบาทที่นี่ด้วยความสามารถในการประมวลผลและทำความเข้าใจกับข้อมูลดังกล่าวตามขนาด พวกเขาสามารถจัดการงานต่างๆ เช่น การวิเคราะห์ความรู้สึก การจัดหมวดหมู่ข้อความ การดึงข้อมูล และอื่นๆ ซึ่งให้ข้อมูลเชิงลึกที่มีค่า
ไม่ว่าจะเป็นการระบุแนวโน้มจากโพสต์บนโซเชียลมีเดียหรือการประเมินความรู้สึกของลูกค้าจากบทวิจารณ์ LLM ช่วยให้ธุรกิจสำรวจข้อมูลที่ไม่มีโครงสร้างจำนวนมากและตัดสินใจโดยใช้ข้อมูลเป็นหลัก
การขยายตัวของตลาด NLP
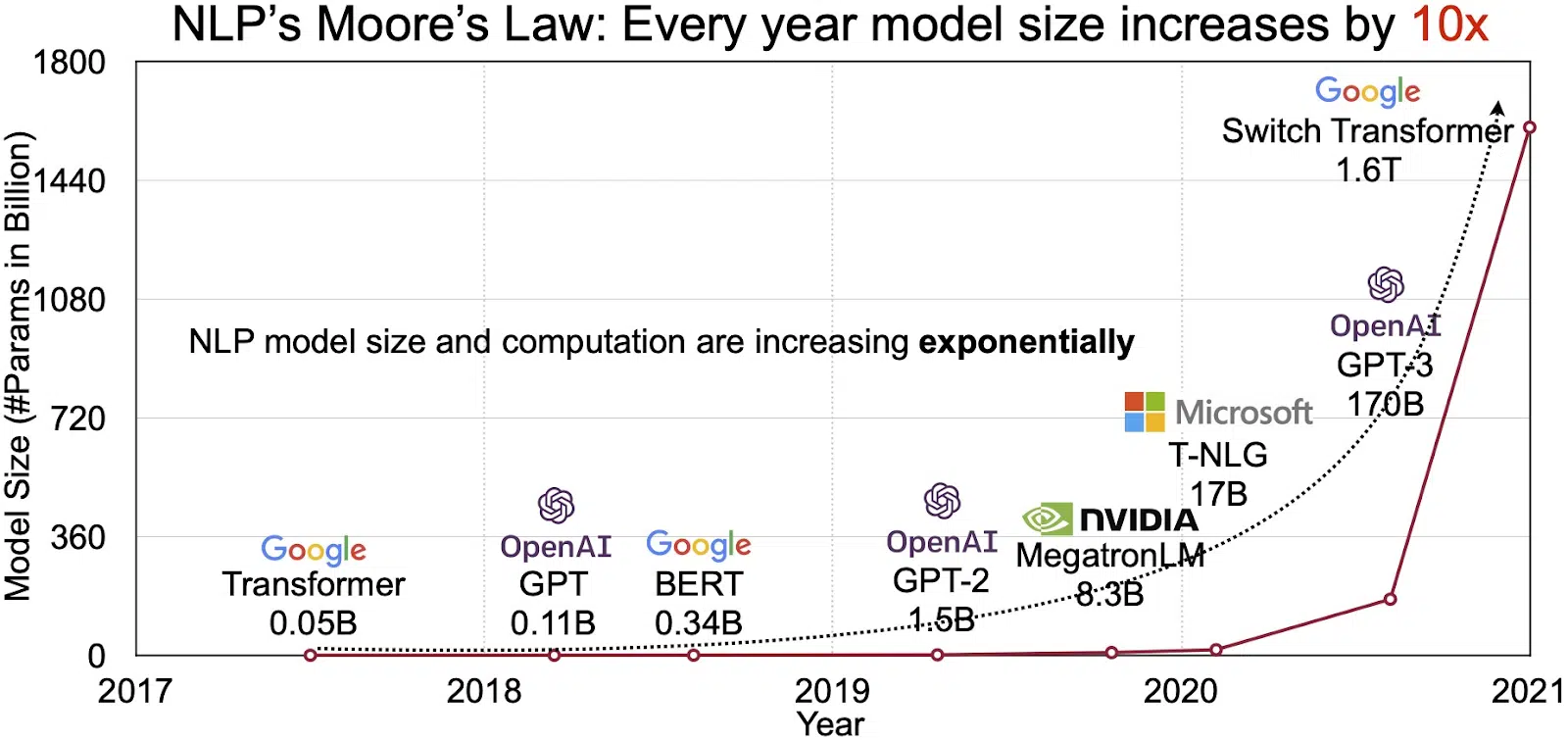
ศักยภาพของ LLM สะท้อนให้เห็นในตลาดที่กำลังเติบโตอย่างรวดเร็วสำหรับการประมวลผลภาษาธรรมชาติ (NLP) นักวิเคราะห์คาดการณ์ว่าตลาด NLP จะขยายตัวจาก 11 หมื่นล้านดอลลาร์ในปี 2020 เป็น 35 หมื่นล้านดอลลาร์ในปี 2026. แต่ไม่ใช่แค่ขนาดตลาดเท่านั้นที่ขยายตัว โมเดลเองก็เติบโตเช่นกัน ทั้งขนาดจริงและจำนวนพารามิเตอร์ที่จัดการ วิวัฒนาการของ LLM ในช่วงหลายปีที่ผ่านมาดังที่แสดงในรูปด้านล่าง (แหล่งที่มาของภาพ: ลิงก์) ตอกย้ำความซับซ้อนและความสามารถที่เพิ่มขึ้น
กรณีการใช้งานยอดนิยมของโมเดลภาษาขนาดใหญ่
นี่คือกรณีการใช้งานยอดนิยมและแพร่หลายที่สุดของ LLM:
- การสร้างข้อความภาษาธรรมชาติ: โมเดลภาษาขนาดใหญ่ (LLMs) รวมพลังของปัญญาประดิษฐ์และภาษาศาสตร์เชิงคำนวณเพื่อสร้างข้อความในภาษาธรรมชาติอย่างอิสระ สามารถตอบสนองความต้องการที่หลากหลายของผู้ใช้ เช่น เขียนบทความ เขียนเพลง หรือมีส่วนร่วมในการสนทนากับผู้ใช้
- การแปลผ่านเครื่อง: สามารถใช้ LLM อย่างมีประสิทธิภาพในการแปลข้อความระหว่างคู่ภาษาใดก็ได้ โมเดลเหล่านี้ใช้ประโยชน์จากอัลกอริทึมการเรียนรู้เชิงลึก เช่น โครงข่ายประสาทเทียมที่เกิดขึ้นซ้ำ เพื่อทำความเข้าใจโครงสร้างทางภาษาของทั้งภาษาต้นทางและภาษาเป้าหมาย จึงช่วยอำนวยความสะดวกในการแปลข้อความต้นฉบับเป็นภาษาที่ต้องการ
- การสร้างเนื้อหาต้นฉบับ: LLM ได้เปิดช่องทางให้เครื่องจักรสร้างเนื้อหาที่เหนียวแน่นและมีเหตุผล เนื้อหานี้สามารถใช้เพื่อสร้างบล็อกโพสต์ บทความ และเนื้อหาประเภทอื่นๆ แบบจำลองใช้ประโยชน์จากประสบการณ์การเรียนรู้เชิงลึกอย่างลึกซึ้งเพื่อจัดรูปแบบและโครงสร้างเนื้อหาในลักษณะที่แปลกใหม่และเป็นมิตรกับผู้ใช้
- วิเคราะห์ความรู้สึก: แอปพลิเคชั่นที่น่าสนใจอย่างหนึ่งของ Large Language Models คือการวิเคราะห์ความรู้สึก ในกรณีนี้ แบบจำลองได้รับการฝึกฝนให้จดจำและจัดหมวดหมู่สถานะทางอารมณ์และความรู้สึกที่มีอยู่ในข้อความที่มีคำอธิบายประกอบ ซอฟต์แวร์สามารถระบุอารมณ์ต่างๆ เช่น เชิงบวก การปฏิเสธ ความเป็นกลาง และความรู้สึกที่ซับซ้อนอื่นๆ สิ่งนี้สามารถให้ข้อมูลเชิงลึกที่มีค่าเกี่ยวกับความคิดเห็นของลูกค้าและมุมมองเกี่ยวกับผลิตภัณฑ์และบริการต่างๆ
- ทำความเข้าใจ สรุป และจำแนกข้อความ: LLM สร้างโครงสร้างที่ใช้งานได้สำหรับซอฟต์แวร์ AI เพื่อตีความข้อความและบริบท ด้วยการสั่งให้โมเดลเข้าใจและกลั่นกรองข้อมูลจำนวนมหาศาล LLM ช่วยให้โมเดล AI สามารถเข้าใจ สรุป และแม้แต่จัดหมวดหมู่ข้อความในรูปแบบและรูปแบบที่หลากหลาย
- ตอบคำถาม: โมเดลภาษาขนาดใหญ่จัดเตรียมระบบการตอบคำถาม (QA) ที่มีความสามารถในการรับรู้และตอบสนองต่อข้อความค้นหาที่เป็นภาษาธรรมชาติของผู้ใช้ได้อย่างแม่นยำ ตัวอย่างยอดนิยมของกรณีการใช้งานนี้ ได้แก่ ChatGPT และ BERT ซึ่งตรวจสอบบริบทของข้อความค้นหาและกลั่นกรองผ่านชุดข้อความจำนวนมากเพื่อส่งมอบคำตอบที่เกี่ยวข้องกับคำถามของผู้ใช้

การติดแท็ก Part-of-Speech (POS)
คำในประโยคถูกแท็กด้วยฟังก์ชันทางไวยากรณ์ เช่น คำกริยา คำนาม คำคุณศัพท์ ฯลฯ กระบวนการนี้ช่วยให้แบบจำลองเข้าใจไวยากรณ์และการเชื่อมโยงระหว่างคำ

การรับรู้ชื่อนิติบุคคล (NER)
เอนทิตีที่มีชื่อ เช่น องค์กร สถานที่ และบุคคลภายในประโยคจะถูกทำเครื่องหมาย แบบฝึกหัดนี้ช่วยแบบจำลองในการตีความความหมายของคำและวลี และให้คำตอบที่แม่นยำยิ่งขึ้น

การวิเคราะห์ความเชื่อมั่น
ข้อมูลข้อความถูกกำหนดป้ายกำกับความรู้สึก เช่น เชิงบวก เป็นกลาง หรือเชิงลบ ช่วยให้ตัวแบบเข้าใจความรู้สึกแฝงของประโยค มีประโยชน์อย่างยิ่งในการตอบคำถามเกี่ยวกับอารมณ์และความคิดเห็น
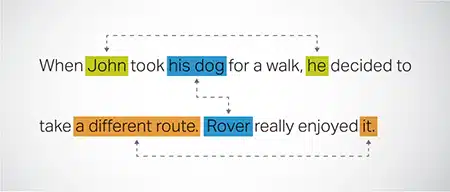
ความละเอียดของแกนอ้างอิง
การระบุและแก้ไขกรณีที่เอนทิตีเดียวกันถูกอ้างถึงในส่วนต่างๆ ของข้อความ ขั้นตอนนี้ช่วยให้แบบจำลองเข้าใจบริบทของประโยค ซึ่งนำไปสู่การตอบสนองที่สอดคล้องกัน
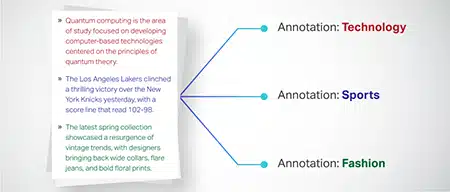
การจัดประเภทข้อความ
ข้อมูลข้อความจะถูกจัดหมวดหมู่เป็นกลุ่มที่กำหนดไว้ล่วงหน้า เช่น บทวิจารณ์ผลิตภัณฑ์หรือบทความข่าว สิ่งนี้ช่วยนางแบบแยกแยะประเภทหรือหัวข้อของข้อความ ทำให้เกิดการตอบสนองที่เกี่ยวข้องมากขึ้น
ข้อเสนอของ Shaip
ไชยป์ เสนอบริการที่หลากหลายเพื่อช่วยให้องค์กรจัดการ วิเคราะห์ และใช้ประโยชน์สูงสุดจากข้อมูลของตน
การขูดเว็บข้อมูล
บริการหลักอย่างหนึ่งที่ Shaip นำเสนอคือการขูดข้อมูล สิ่งนี้เกี่ยวข้องกับการดึงข้อมูลจาก URL เฉพาะโดเมน ด้วยการใช้เครื่องมือและเทคนิคอัตโนมัติ Shaip สามารถขูดข้อมูลปริมาณมากจากเว็บไซต์ต่างๆ คู่มือผลิตภัณฑ์ เอกสารทางเทคนิค ฟอรัมออนไลน์ บทวิจารณ์ออนไลน์ ข้อมูลการบริการลูกค้า เอกสารกำกับดูแลอุตสาหกรรม ฯลฯ ได้อย่างรวดเร็วและมีประสิทธิภาพ กระบวนการนี้มีประโยชน์อย่างยิ่งสำหรับธุรกิจเมื่อ รวบรวมข้อมูลที่เกี่ยวข้องและเฉพาะเจาะจงจากแหล่งข้อมูลมากมาย

การแปลด้วยเครื่อง
พัฒนาแบบจำลองโดยใช้ชุดข้อมูลหลายภาษาที่จับคู่กับการถอดความที่สอดคล้องกันสำหรับการแปลข้อความในภาษาต่างๆ กระบวนการนี้ช่วยขจัดอุปสรรคทางภาษาและส่งเสริมการเข้าถึงข้อมูล
การสกัดและการสร้างอนุกรมวิธาน
Shaip สามารถช่วยในการแยกอนุกรมวิธานและการสร้าง สิ่งนี้เกี่ยวข้องกับการจำแนกและจัดหมวดหมู่ข้อมูลในรูปแบบที่มีโครงสร้างซึ่งสะท้อนถึงความสัมพันธ์ระหว่างจุดข้อมูลต่างๆ สิ่งนี้มีประโยชน์อย่างยิ่งสำหรับธุรกิจในการจัดระเบียบข้อมูล ทำให้เข้าถึงได้มากขึ้นและวิเคราะห์ได้ง่ายขึ้น ตัวอย่างเช่น ในธุรกิจอีคอมเมิร์ซ ข้อมูลผลิตภัณฑ์อาจถูกจัดหมวดหมู่ตามประเภทผลิตภัณฑ์ แบรนด์ ราคา ฯลฯ ทำให้ลูกค้าสามารถสำรวจแค็ตตาล็อกผลิตภัณฑ์ได้ง่ายขึ้น
การเก็บรวบรวมข้อมูล
บริการรวบรวมข้อมูลของเราให้ข้อมูลที่สำคัญในโลกแห่งความจริงหรือข้อมูลสังเคราะห์ที่จำเป็นสำหรับการฝึกอัลกอริทึม AI เชิงกำเนิด และปรับปรุงความแม่นยำและประสิทธิภาพของโมเดลของคุณ ข้อมูลมีแหล่งที่มาอย่างเป็นกลาง มีจริยธรรม และมีความรับผิดชอบ โดยคำนึงถึงความเป็นส่วนตัวและความปลอดภัยของข้อมูล

คำถาม & คำตอบ
การตอบคำถาม (QA) เป็นฟิลด์ย่อยของการประมวลผลภาษาธรรมชาติที่เน้นการตอบคำถามโดยอัตโนมัติในภาษามนุษย์ ระบบ QA ได้รับการฝึกอบรมเกี่ยวกับข้อความและรหัสที่ครอบคลุม ทำให้สามารถจัดการกับคำถามประเภทต่างๆ รวมถึงคำถามเชิงข้อเท็จจริง คำจำกัดความ และความคิดเห็น ความรู้ด้านโดเมนมีความสำคัญต่อการพัฒนาโมเดล QA ที่ปรับให้เหมาะกับสาขาเฉพาะ เช่น การสนับสนุนลูกค้า การดูแลสุขภาพ หรือซัพพลายเชน อย่างไรก็ตาม วิธีการสร้าง QA ช่วยให้แบบจำลองสามารถสร้างข้อความได้โดยไม่ต้องมีความรู้ด้านโดเมน โดยขึ้นอยู่กับบริบทเพียงอย่างเดียว
ทีมผู้เชี่ยวชาญของเราสามารถศึกษาเอกสารหรือคู่มือที่ครอบคลุมอย่างละเอียดถี่ถ้วนเพื่อสร้างคู่คำถาม-คำตอบ อำนวยความสะดวกในการสร้าง Generative AI สำหรับธุรกิจ วิธีการนี้สามารถจัดการกับข้อสงสัยของผู้ใช้ได้อย่างมีประสิทธิภาพโดยการขุดข้อมูลที่เกี่ยวข้องจากคลังข้อมูลที่กว้างขวาง ผู้เชี่ยวชาญที่ผ่านการรับรองของเรารับประกันว่าจะมีคู่คำถามและคำตอบที่มีคุณภาพสูงสุดซึ่งครอบคลุมหัวข้อและโดเมนที่หลากหลาย

สรุปข้อความ
ผู้เชี่ยวชาญของเราสามารถกลั่นกรองบทสนทนาที่ครอบคลุมหรือบทสนทนาที่มีความยาว นำเสนอบทสรุปที่กระชับและลึกซึ้งจากข้อมูลที่เป็นข้อความจำนวนมาก

การสร้างข้อความ
ฝึกโมเดลโดยใช้ชุดข้อมูลข้อความกว้างๆ ในรูปแบบต่างๆ เช่น บทความข่าว เรื่องแต่ง และบทกวี จากนั้นโมเดลเหล่านี้สามารถสร้างเนื้อหาประเภทต่างๆ รวมถึงบทความข่าว รายการบล็อก หรือโพสต์บนโซเชียลมีเดีย นำเสนอโซลูชันที่คุ้มค่าและประหยัดเวลาสำหรับการสร้างเนื้อหา
การรู้จำเสียง
พัฒนาแบบจำลองที่สามารถเข้าใจภาษาพูดสำหรับการใช้งานต่างๆ ซึ่งรวมถึงผู้ช่วยที่สั่งงานด้วยเสียง ซอฟต์แวร์เขียนตามคำบอก และเครื่องมือแปลแบบเรียลไทม์ กระบวนการเกี่ยวข้องกับการใช้ชุดข้อมูลที่ครอบคลุมซึ่งประกอบด้วยการบันทึกเสียงของภาษาพูด จับคู่กับการถอดเสียงที่สอดคล้องกัน

คำแนะนำสินค้า
พัฒนาแบบจำลองโดยใช้ชุดข้อมูลที่กว้างขวางของประวัติการซื้อของลูกค้า รวมถึงฉลากที่ชี้ให้เห็นถึงผลิตภัณฑ์ที่ลูกค้ามีแนวโน้มที่จะซื้อ เป้าหมายคือการให้คำแนะนำที่ถูกต้องแก่ลูกค้า ซึ่งจะเป็นการกระตุ้นยอดขายและเพิ่มความพึงพอใจของลูกค้า
คำบรรยายภาพ
ปฏิวัติกระบวนการตีความภาพของคุณด้วยบริการคำบรรยายภาพที่ขับเคลื่อนด้วย AI อันทันสมัยของเรา เราใส่ความมีชีวิตชีวาลงในรูปภาพโดยสร้างคำอธิบายที่ถูกต้องและมีความหมายตามบริบท นี่เป็นการปูทางสำหรับการมีส่วนร่วมและความเป็นไปได้ในการโต้ตอบกับเนื้อหาภาพของคุณสำหรับผู้ชมของคุณ

การฝึกอบรมบริการแปลงข้อความเป็นคำพูด
เรามีชุดข้อมูลที่ครอบคลุมซึ่งประกอบด้วยการบันทึกเสียงพูดของมนุษย์ ซึ่งเหมาะสำหรับการฝึกอบรมโมเดล AI รุ่นเหล่านี้สามารถสร้างเสียงที่เป็นธรรมชาติและน่าดึงดูดใจสำหรับแอปพลิเคชันของคุณ จึงมอบประสบการณ์เสียงที่โดดเด่นและชวนดื่มด่ำให้กับผู้ใช้ของคุณ



