



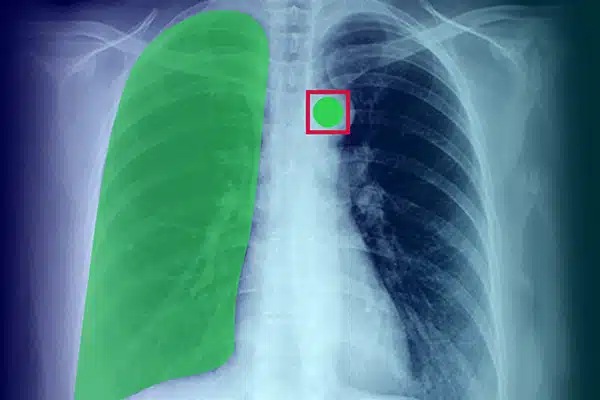
คำอธิบายประกอบรูปภาพ
ปรับปรุง AI ทางการแพทย์โดยการใส่คำอธิบายประกอบข้อมูลภาพจากรังสีเอกซ์ การสแกน CT และ MRI ตรวจสอบให้แน่ใจว่าโมเดล AI ทำงานได้ดีเยี่ยมในการวินิจฉัยและการรักษา ตามคำแนะนำของการติดป้ายกำกับข้อมูลของผู้เชี่ยวชาญ รับผลลัพธ์ของผู้ป่วยที่ดีขึ้นด้วยข้อมูลเชิงลึกด้านการถ่ายภาพที่เหนือกว่า
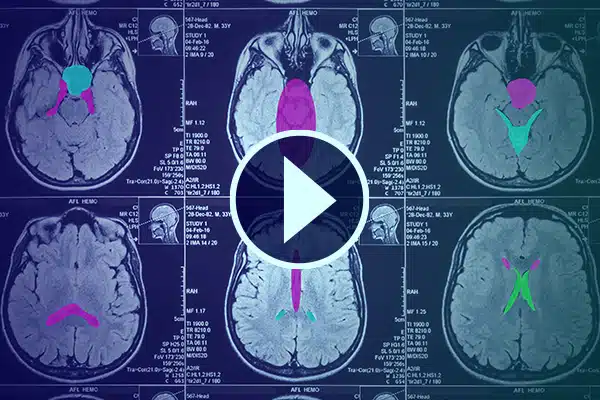
คำอธิบายประกอบวิดีโอ
พัฒนา AI ในการดูแลสุขภาพด้วยคำอธิบายประกอบวิดีโอโดยละเอียด ปรับปรุงการเรียนรู้ AI ด้วยการแบ่งประเภทและการแบ่งส่วนในฟุตเทจทางการแพทย์ ปรับปรุง AI การผ่าตัดและการติดตามผู้ป่วยเพื่อการส่งมอบและการวินิจฉัยด้านการดูแลสุขภาพที่ดีขึ้น
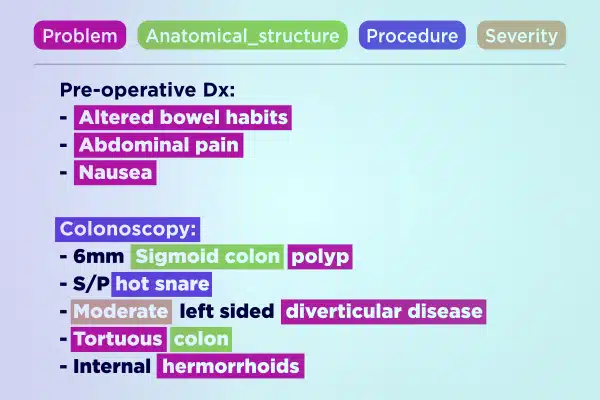
คำอธิบายประกอบข้อความ
ปรับปรุงการพัฒนา AI ทางการแพทย์ด้วยข้อมูลข้อความที่มีคำอธิบายประกอบอย่างเชี่ยวชาญ แยกวิเคราะห์และเพิ่มปริมาณข้อความจำนวนมากอย่างรวดเร็ว ตั้งแต่บันทึกที่เขียนด้วยลายมือไปจนถึงรายงานประกันภัย รับรองข้อมูลเชิงลึกที่ถูกต้องและนำไปปฏิบัติได้สำหรับความก้าวหน้าด้านการดูแลสุขภาพ

คำอธิบายประกอบเสียง
ใช้ประโยชน์จากความเชี่ยวชาญ NLP เพื่อใส่คำอธิบายประกอบและติดป้ายกำกับข้อมูลเสียงทางการแพทย์อย่างถูกต้อง ประดิษฐ์ระบบช่วยเหลือด้วยเสียงเพื่อการดำเนินงานทางคลินิกที่ราบรื่น และผสานรวม AI เข้ากับผลิตภัณฑ์ดูแลสุขภาพที่สั่งงานด้วยเสียงต่างๆ เพิ่มความแม่นยำในการวินิจฉัยด้วยการดูแลจัดการข้อมูลเสียงจากผู้เชี่ยวชาญ

การเข้ารหัสทางการแพทย์
ปรับปรุงเอกสารทางการแพทย์โดยแปลงเป็นรหัสสากลด้วยการเข้ารหัสทางการแพทย์ของ AI รับประกันความถูกต้อง เพิ่มประสิทธิภาพการเรียกเก็บเงิน และสนับสนุนการส่งมอบบริการดูแลสุขภาพที่ราบรื่นด้วยความช่วยเหลือ AI ที่ล้ำสมัยในการเขียนโค้ดเวชระเบียน

เฟส 1: ความเชี่ยวชาญด้านเทคนิคของโดเมน (ทำความเข้าใจเกี่ยวกับขอบเขตและแนวทางการทำหมายเหตุประกอบ)

เฟส 2: การฝึกอบรมทรัพยากรที่เหมาะสมสำหรับโครงการ

เฟส 3: รอบการตอบรับและ QA ของเอกสารที่มีคำอธิบายประกอบ
รังสีวิทยา
บริการคำอธิบายประกอบภาพรังสีวิทยาของเราทำให้การวินิจฉัย AI คมชัดขึ้น และรวมถึงความเชี่ยวชาญเพิ่มเติมอีกชั้นหนึ่ง การสแกน X-ray, MRI และ CT แต่ละครั้งจะมีการติดป้ายกำกับและตรวจสอบอย่างพิถีพิถันโดยผู้เชี่ยวชาญเฉพาะด้าน ขั้นตอนพิเศษในการฝึกอบรมและการทบทวนนี้ช่วยเพิ่มความสามารถของ AI ในการตรวจจับความผิดปกติและโรคต่างๆ ช่วยเพิ่มความแม่นยำก่อนส่งมอบให้กับลูกค้าของเรา

โรคหัวใจและหลอดเลือด
คำอธิบายประกอบภาพที่เน้นด้านหทัยวิทยาของเราทำให้การวินิจฉัย AI คมชัดยิ่งขึ้น เรานำผู้เชี่ยวชาญด้านหทัยวิทยาที่ติดป้ายกำกับภาพที่ซับซ้อนเกี่ยวกับหัวใจและฝึกอบรมโมเดล AI ของเรา ก่อนที่เราส่งข้อมูลไปยังลูกค้า ผู้เชี่ยวชาญเหล่านี้จะตรวจสอบแต่ละภาพเพื่อให้แน่ใจว่ามีความถูกต้องแม่นยำสูงสุด กระบวนการนี้ช่วยให้ AI ตรวจจับสภาวะของหัวใจได้แม่นยำยิ่งขึ้น
การทำฟัน
บริการใส่คำอธิบายประกอบภาพของเราในฉลากทันตกรรม ภาพทางทันตกรรมเพื่อเพิ่มประสิทธิภาพเครื่องมือวินิจฉัย AI ด้วยการระบุฟันผุ ปัญหาการเรียงตัวของฟัน และสภาพทันตกรรมอื่นๆ ที่แม่นยำ SME ของเราช่วยให้ AI ปรับปรุงผลลัพธ์ของผู้ป่วยและสนับสนุนทันตแพทย์ในการวางแผนการรักษาที่แม่นยำและการตรวจหาตั้งแต่เนิ่นๆ


















คน
ทีมงานที่ทุ่มเทและฝึกฝน:
- ผู้ทำงานร่วมกันกว่า 30,000 รายสำหรับการสร้างข้อมูล ติดฉลาก & QA
- ทีมผู้บริหารโครงการที่ได้รับการรับรอง
- ทีมพัฒนาผลิตภัณฑ์ที่มีประสบการณ์
- Talent Pool Sourcing & ทีมออนบอร์ด

กระบวนการ
มั่นใจได้ถึงประสิทธิภาพของกระบวนการสูงสุดด้วย:
- กระบวนการ 6 Sigma Stage-Gate อันแข็งแกร่ง
- ทีมงานสายดำ 6 Sigma โดยเฉพาะ – เจ้าของกระบวนการหลัก & การปฏิบัติตามข้อกำหนดด้านคุณภาพ
- การปรับปรุงอย่างต่อเนื่อง & ลูปคำติชม Feedback

ระบบปฏิบัติการ
แพลตฟอร์มที่ได้รับสิทธิบัตรให้ประโยชน์:
- แพลตฟอร์มแบบ end-to-end บนเว็บ
- คุณภาพไร้ที่ติ
- ททท.เร็วขึ้น Fast
- การจัดส่งที่ราบรื่น



